INTERNET MARKETING SUCCESS


Getting backlinks is one of the most challenging and time-consuming tasks in SEO. So how do you get started on creating a successful outreach program that brings in quality links? Join Purelinq’s Kevin Rowe, who will walk you through creating a scalable outreach program to create a natural link profile, meet minimum quality requirements and drive maximum impact. Register today for “Everything You Should Know About Building Quality Links at Scale,” presented by Purelinq. The post SEO webinar on getting quality backlinks appeared first on Search Engine Land. via Search Engine Land https://ift.tt/icq7Oj3
0 Comments
What you’re about to read is not actually from me. It’s a compilation of PPC-specific lessons learned by those who actually do the work every day in this age of machine learning automation. Before diving in, a few notes:
Lesson 1: Volume is critical to an automated strategyIt’s simple, a machine cannot optimize toward a goal if there isn’t enough data to find patterns. For example, Google Ads may recommend “Maximize Conversions” as a bid strategy, BUT the budget is small (like sub $2,000/mo) and the clicks are expensive. In a case like this, you have to give it a Smart Bid strategy goal capable of collecting data to optimize towards. So a better option might be to consider “Maximize Clicks” or “Search Impression Share”. In small volume accounts, that can make more sense. Lesson 2: Proper learning expectationsThe key part of “machine learning” is the second word: “learning.” For a machine to learn what works, it must also learn what doesn’t work. That part can be agonizing. When launching an initial Responsive Search Ad (RSA), expect the results to underwhelm you. The system needs data to learn the patterns of what works and doesn’t. It’s important for you to set these expectations for yourself and your stakeholders. A real-life client example saw the following results:
As you can see, month two looked far better. Have the proper expectations set! Lesson 3: Old dogs need to learn new tricksMany of us who’ve been in the industry a while weren’t taught to manage ad campaigns the way they need to be run now. In fact, it was a completely different mindset. For example, I was taught to:
Lesson 4: Stay on top of any site changesAny type of automation relies on proper inputs. Sometimes what would seem to be a simple change could do significant damage to a campaign. Some of those changes include:
Those are just a few examples, but they all happened and they all messed with a live campaign. Just remember, all bets are off when any site change happens without your knowledge! Lesson 5: Recommendations tabThe best advice to follow regarding Recommendations are the following:

Lesson 6: Closely watch Search Impression Share, regardless of your goalOfficially defined as “the impressions you’ve received on the Search Network divided by the estimated number of impressions you were eligible to receive,” Search Impression Share is basically a gauge to inform you what percentage of the demand you are showing to compete for. This isn’t to imply “Search Impression Share” is the single most important metric. However, you might implement a smart bidding rule with “Performance Max” or “Maximize Conversions” and doing so may negatively impact other metrics (like “Search Impression Share”). That alone isn’t wrong. But make sure you’re both aware and OK with that. Lesson 7: Stay on top of changes (to the ad platforms)Sometimes things change. It’s your job to stay on top of it. For smart bidding, “Target CPA” no longer exists for new campaigns. It’s now merged with “Maximize Conversions”. Smart Shopping and Local Campaigns are being automatically updated to “Performance Max” between July and September 2022. If you’re running these campaigns, the best thing you can do is to do the update manually yourself (one click implementation via the “recommendations” tab in your account). Why should you do this?
Lesson 8: Keep separate records of your rulesThis doesn’t need to be complicated. Just use your favorite tool like Evernote, OneNote, Google Docs/Sheets, etc. Include the following for each campaign:
There are three critical reasons why this is a good idea:
Lesson 9: Reporting isn’t always actionableImagine you’re setting up a campaign and loading snippets of an ad. You’ve got:
Given the above conditions, do you think it would be at all useful to know which combinations performed best? Would it help you to know if a consistent trend or theme emerges? Wouldn’t having that knowledge help you come up with even more effective snippets of an ad to test going forward? Well, too bad because that’s not what you get at the moment. Lesson 10: Bulk upload tools are your friendIf you run a large volume account with a lot of campaigns, then anytime you can provide your inputs in a spreadsheet for a bulk upload you should do it. Just make sure you do a quality check of any bulk actions taken. 
Lesson 11: ALWAYS automate the mundane tasksFew things can drag morale down like a steady stream of mundane tasks. Automate whatever you can. That can include:
Lesson 12: Innovate beyond the default toolsTo an outsider, managing an enterprise level PPC campaign would seem like having one big pile of money to work with for some high-volume campaigns. That’s a nice vision, but the reality is often quite different. For those who manage those campaigns, it can feel more like 30 SMB accounts. You have different regions with several unique business units (each having separate P&L’s). The budgets are set and you cannot go over it. Period. You also need to ensure campaigns run the whole month so you can’t run out of budget on the 15th. Below is an example of a custom budget tracking report built within Google Data Studio that shows the PPC manager how the budget is tracking in the current month: 
Lesson 13: 10% rule of experimentationDevote 10% of your management efforts (not necessarily budget) to trying something new. Try a beta (if you have access to it), a new smart bidding strategy, new creative snippets, new landing page, call to action, etc. Lesson 14: “Pin” when you have toIf you are required (for example by legal, compliance, branding, executives) to always display a specific message in the first headline, you can place a “pin” that will only insert your chosen copy in that spot while the remainder of the ad will function as a typical RSA. Obviously if you “pin” everything, then the ad is no longer responsive. However, it has its place so when you gotta pin, you gotta pin! Lesson 15: The “garbage in, garbage out” (GIGO) rule appliesIt’s simple: The ad platform will perform the heavy lifting to test for the best possible ad snippet combinations submitted by you to achieve an objective defined by you. The platform can either perform that heavy lifting to find the best combination of well-crafted ad snippets or garbage ones. Bottom line, an RSA doesn’t negate the need for skilled ad copywriting. Lesson 16: Educate legal, compliance, & branding teams in highly regulated industriesIf you’ve managed campaigns for an organization in a highly regulated industry (healthcare, finance, insurance, education, etc.) you know all about the legal/compliance review and frustrations that can mount. Remember, you have your objectives (produce campaigns that perform) and they have theirs (to keep the organization out of trouble). When it comes to RSA campaigns, do yourself a favor and educate the legal, compliance, and branding teams on:
Lesson 17: Don’t mistake automate for set and forgetTo use an automotive analogy, think of automation capabilities more like “park assist” than “full self driving.” For example, you set up a campaign to “Bid to Position 2” and then just let it run without giving it a second thought. In the meantime, a new competitor enters the market and showing up in position 2 starts costing you a lot more. Now you’re running into budget limitations. Use automation to do the heavy lifting and automate the mundane tasks (Lesson #11), but ignore a campaign once it’s set up. Lesson 18: You know your business better than the algorithmThis is related to lesson #5 and cannot be overstated. For example, you may see a recommendation to reach additional customers at a similar cost per conversion in a remarketing campaign. Take a close look at the audiences being recommended as you can quickly see a lot of inflated metrics – especially in remarketing. You have the knowledge of the business far better than any algorithm possibly could. Use that knowledge to guide the machine and ensure it stays pointed in the right direction. Lesson 19: The juice may not be worth the squeeze in some accountsBy “some accounts,” I’m mostly referring to low-budget campaigns. Machine learning needs data and so many smaller accounts don’t have enough activity to generate it. For those accounts, just keep it as manual as you can. Lesson 20: See what your peers are doingSpeak with one of your industry peers, and you’ll quickly find someone who understands your daily challenges and may have found ways to mitigate them. Attend conferences and network with people attending the PPC track. Sign up for PPC webinars where tactical campaign management is discussed. Participate (or just lurk) in social media discussions and groups specific to PPC management. Lesson 21: Strategic PPC marketers will be valuableMany of the mundane tasks (Lesson #11) can be automated now, thus eliminating the need for a person to spend hours on end performing them. That’s a good thing – no one really enjoyed doing most of those things anyway. As more “tasks” continue toward the path of automation, marketers only skilled at the mundane work will become less needed. On the flipside, this presents a prime opportunity for strategic marketers to become more valuable. Think about it – the “machine” doing the heavy lifting needs guidance, direction and course corrective action when necessary. That requires the marketer to:
The post 21 PPC lessons learned in the age of machine learning automation appeared first on Search Engine Land. via Search Engine Land https://ift.tt/7d3YFJr 
Responsive Search Ads – RSA for short – are not the new kids on the block. RSAs have been a part of the PPC ecosystem for a few years. That being said, RSAs have been a hot topic in 2022. Why all the hubbub about them now? This summer, the preceding ad type, Expanded Text Ads, is being deprecated. This puts Responsive Search Ads front and center for advertisers as the singular text ad type for search campaigns. Let’s dig in a little bit deeper on RSAs, the change and how you can maximize your potential with RSAs. Why RSAs matterResponsive Search Ads are all about serving the right message at the right time. RSAs are a flexible ad experience that show more customized content to reach your customers. These ads adapt your text ads to closely match what someone is searching for when they search for it. Further, RSAs can help to reduce bulky operations and save time. Advertisers provide up to 15 headlines and up to four descriptions. All of these components can create over 40,000 possible ad permutations! Find efficiency in evaluating ads through A/B tests and automatically determine what creative content works best with different queries. 
Expanded Text Ad deprecationThe deprecation of Expanded Text Ads is coming in two waves this summer. The first wave was for Google Ads on June 30th. The second wave will be Microsoft Advertising. As of August 29th, advertisers will no longer be able to create new Expanded Text Ads. On both platforms, previously existing Expanded Text Ads will continue to serve. Note that though you can toggle these ads on and off, you will no longer be able to edit the ads. Maximize your potential with RSAsHow can you maximize your potential with RSAs? First and foremost, get started by launching RSAs alongside Expanded Text Ads today if you haven’t already. Here are some additional best practices to consider when working with RSAs:
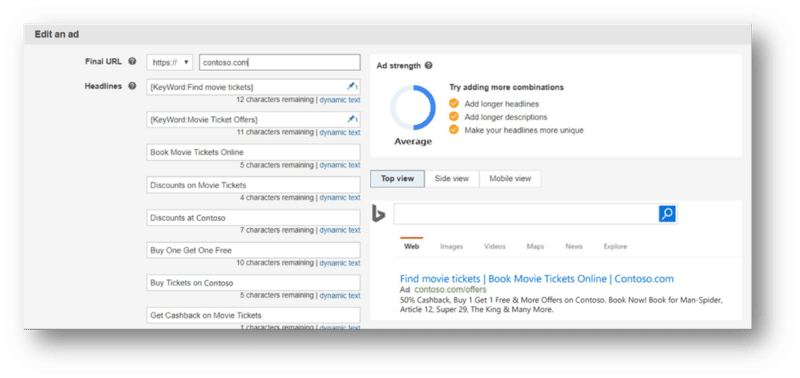
Responsive Search Ads have taken center stage in search campaigns. If you were sleeping on RSAs before, it is time to wake up and take notice. Start creating RSAs to launch alongside your existing Expanded Text Ads today. Happy ad testing, everyone! The post Responsive Search Ads take center stage – are you prepared? appeared first on Search Engine Land. via Search Engine Land https://ift.tt/wO1DLRT Knowledge panels are one of the most coveted, yet mysterious elements in organic search. Brands desire to have their own robust Knowledge Panel entry, but are left with little to no control over what appears in them. By this point, we should all have a basic understanding of entities within Google’s Knowledge Graph. Consider that required reading for this article. Where does Google pull entity data from?We all know that Google pulls information from their Knowledge Graph for knowledge panels, but where do they pull information for the Knowledge Graph? Technically, Google can use information from any crawlable website for their Knowledge Graph. However, we most often see Wikipedia as the dominant source of information. The types of websites Google likes to pull from are typically directory-style websites that provide information that is:
Jason Barnard’s Kalicube has an awesome resource that tracks entity sources for the past 30 days. I referred to this list and many of his articles for guidance on building my knowledge panel and personal entity. 
Why is Wikipedia so prolific?Google tends to use Wikipedia so heavily for a few reasons:
While Wikipedia has skeptics reminding us that anyone can edit an entry, a heavy amount of moderation and editing still takes place on Wikipedia. Given that it’s also a fairly neutral/unbiased source of information, that gives Google all the more reason to trust it. So if it’s so difficult to get an entry, why do so many SEOs only focus on getting a Wikipedia page as their way into the Knowledge Graph? Well, the answer is that once you have a Wikipedia page, it’s almost a guaranteed entry. However, this is a mindset we need to break, because by now, we should all know that there are no guarantees in SEO. Sure you can definitely pursue a Wikipedia page for your own brand, but just make sure to diversify your tactics and don’t just focus on that as your sole strategy. How long does it take to earn a Knowledge Graph entry?Don’t say it depends, don’t say it, don’t say it. Okay, so it is different for everyone. For me, it took about a year since the beginning of my efforts for mine to appear. It all depends on how hard your brand is working and whether or not your brand deserves one. Did I try that hard? Not really. Did I deserve one? Not at all. But based on the specific steps I took to market myself in the industry, I just so happened to earn a Knowledge Panel in the process. I never thought I’d actually get one, but decided to run a series of tests to see if it would actually work, and to my surprise it did. The specific steps I took to earn my knowledge panelOkay now that you’ve probably scrolled past all of my intro content, let’s get to what you came here for. What specifically did I do to earn my Knowledge Panel entry and get established in Google’s Knowledge Graph? Here are the specific steps I took in order. 1. Established entity homeThe first step is to establish your root or home of your entity. This could be your personal website, brand’s page, author page, or anything that is the truest source of information for the entity. For me, I chose my personal website’s homepage for my entity home. On my homepage, I did two specific things to help search engines: Created ‘About Me’ Content I created a one-sentence “about me” that I planned to use on all bio information across the web. Almost all of my personal bios on different websites I’m featured on start with this sentence. This creates consistency on who I am and what I do. Create bulleted list of work Having a short, easy to crawl, list of what I do helps create a connection to myself and other entities. My hope was Google would understand that I could be found on those other websites and better understand the relationship between myself and those entities. More on this in the schema section. 
2. Industry authorshipFor the past four years, I’ve been featured on dozens of podcasts and written plenty of articles for Search Engine Land, Search Engine Journal, OnCrawl, and many mory! All of my features come with an author page, which has a list of all my articles for that site as well as Person schema for that site. Additionally, all of my author pages contain a link back to my entity home, which is critically important for building your brand’s entity relevancy. 3. Consistent schemaSchema markup is the connective tissue that brings all of my authorship together. On my entity home, I ensured that I have robust schema markup. The most important thing to include in the schema markup is the SameAs data which I directed to all of my most important features on the web. I ensured to add SameAs links to any sources that I’ve seen generate entities in the past. Below is a screenshot of what you’ll see if you run my personal website through the Schema Markup validator. 
The specific schema type I chose was Person, as this was most accurate to myself. If you’re creating an entity for your business or brand, try to choose the schema type that’s most accurate to your business. Typically, I create schema from scratch for all of my clients. However, Yoast’s author/person schema provided exactly what I was looking for and included one important feature. What Yoast did for me was instead of making a generic Organization schema type for my website, I marked my website as a Person. Within the specific settings, I pasted all of my important links into the contact info fields. Please note that other than Twitter, you can paste any link in those fields. 
4. Consistent linkingSchema plays a huge factor in creating an interconnected web of consistent information for Google’s Knowledge Graph. However, external links provide even greater trust signals. On my website, I have a collections page that links out to all of my important work. It’s like a mini CV of my work for anyone who wants to work with me. However, you can’t just link out to other places on your website, you need established entities linking back to you. That’s why all of my featured podcasts and author pages have a link back to my website. Not only are they linking back to my website, they’re all linking to my homepage, which I’ve established as my entity home. 5. DirectoriesThis can definitely help get an easy foot in the door for many people and brands trying to get established with their own knowledge panel. One of the biggest directories that I recommend getting established in is Crunchbase. In fact, Crushbase is what was listed as the source data during the first iteration of my knowledge panel. I’ve seen many startups get their first knowledge panel entry through Crunchbase and it seems to be a consistently high source for Google to rely on. This is because Crunchbase has some verification processes that make it slightly more challenging to create spam in bulk. When getting started with building out your directories, focus on the niche ones that are most relevant to your industry. This will go a lot farther for you than Crunchbase or any other big ones. The different iterations my knowledge panel has shownOver the course of about 1-2 months, Google has used a variety of different sources to feed my knowledge panel. It’s been very interesting to see how it’s evolved over such a short amount of time. I’ve even had my own article carousel which has since disappeared. First iteration: All crunch, no flavorAt first, Crunchbase was the source of my entire knowledge panel entry. Something I found amusing is that there’s no link for my LinkedIn page, it’s just the anchor text on Crunchbase. This was a great win for me and I was pleased with how structured the knowledge panel was. 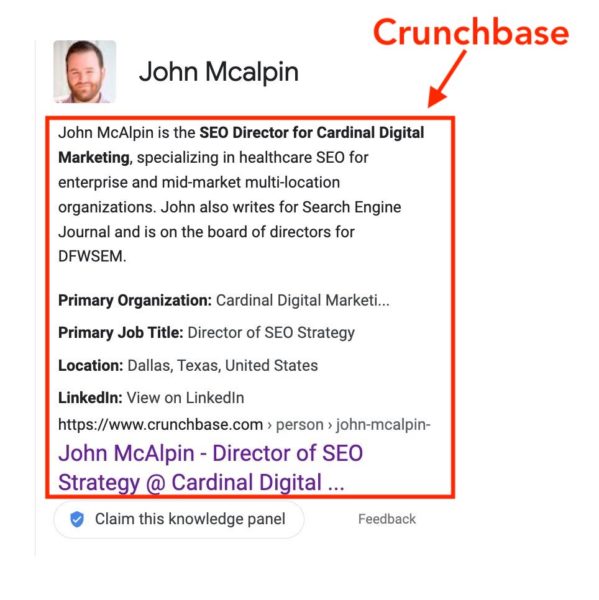
I tested a few queries to see how my entity data would appear as a zero-click result. Testing searches: “Who is John McAlpin?” This result was a little disappointing as it brought up a different John McAlpin who was referenced in a press release. However, I did see my entity in a side panel, which was both surprising and exciting. 
Testing searches: “Where Does John McAlpin Work?” This was a much more accurate result, but also a surprising one. If Crunchbase was fueling most of my knowledge panel data, why was Google showing Search Engine Journal as the source for this featured snippet? We could speculate all day on our theories of how Google came to this decision, but I was just glad to see a more accurate result here. 
Second iteration: Images getting comicalA few weeks after the first sighting of my Knowledge Panel, I see a few interesting updates:
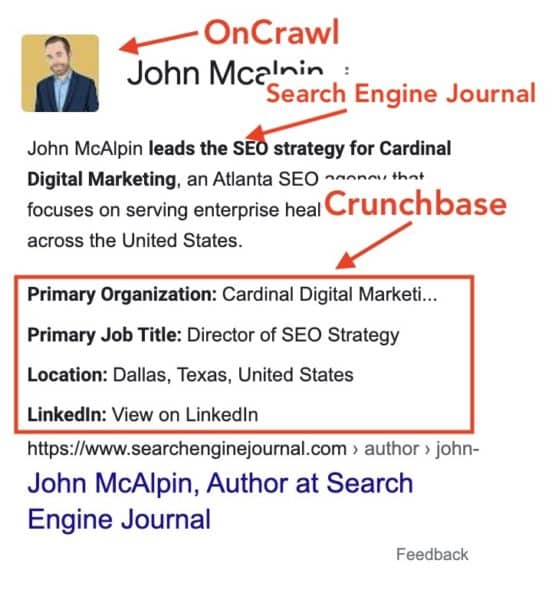
Third iteration: Image correctionUnhappy with my image being a cartoon for my professional headshot, I submitted feedback to update the image. I chose my image from Search Engine Land and sure enough it updated it about two weeks later. 
Key takeawaysWhen seeking to earn your own knowledge panel, it’s important to keep in mind a few things.
The post How I earned a knowledge panel without a Wikipedia page appeared first on Search Engine Land. via Search Engine Land https://ift.tt/C1NwnGc 
QR codes are shaking up the marketing world (did you see that Coinbase Superbowl commercial?). This seminar will teach you everything you need to know about how QR codes can be used to unlock mobile engagement and revenue, channel attribution, and first-party data in a cookieless world. Join QR marketing expert Brian Klais, CEO of URLgenius, to learn enterprise-grade QR strategies and best practices you won’t hear anywhere else and change how you think about QR code opportunities. Register today for “Unlock the Cutting-Edge Potential of QR Codes” presented by URLgenius. The post Webinar: The genius behind QR-code marketing appeared first on Search Engine Land. via Search Engine Land https://ift.tt/0pZlHcR Google has made a variety of significant updates to its Search Quality Rater Guidelines. The most significant overhauls were to Google’s definitions of YMYL (Your Money, Your Life), and the extent to which E-A-T matters as a matter of page quality. Google provided new, clear definitions for what it means for content to be YMYL, mostly framed around the extent to which the content can cause harm to individuals or society. Google also provided a new table establishing clear examples of what it means for content to be YMYL or not. In the new guidelines, Google also explained that for highly YMYL content – E-A-T is crucial above all other factors. It also explained that it’s possible to have low-quality content on otherwise trustworthy and authoritative sites. Your Money, Your Life (YMYL) Topics – Section 2.3Google completely reframed its definition of YMYL (Your Money, Your Life). In the previous version of the Quality Rater Guidelines, YMYL topics were broken down into the following categories:
Google completely removed these categories. The new version of the Quality Rater Guidelines now defines YMYL by its potential to cause harm. Topics that present a “high risk of harm,” can significantly impact the “health, financial stability, or safety of people, or the welfare or well-being of society.” Google then defines who may be harmed by YMYL content, including the person viewing the content, other people affected by the viewer, or groups of people or society as a whole. This could potentially be in reference to violent, extremist or terrorist content. 
Google then defines YMYL topics as either being inherently dangerous (violent extremism), or harmful because presenting misinformation related to the topic can be harmful. For example, providing bad advice related to heart attacks, investments or earthquakes could cause harm to the user. Instead of listing individual categories that may be considered YMYL, as in previous versions of the guidelines, Google now asks quality raters to think of YMYL in terms of four types of harm YMYL content can cause for individuals or society:
In another new addition, Google claims that a “hypothetical harmful page” about a non-harmful topic, such as the “science behind rainbows,” is technically not considered YMYL. According to their updated definition, the content must have the potential to cause harm or otherwise impact peoples’ well-being. In another big update, Google claims that many or most updates are not YMYL because they do not have the potential to cause harm. Google also stated for the first time that YMYL assessment is done on a spectrum. To clarify these new statements, Google provided a new table on page 12 of the guidelines, which specifically delineates the types of topics that Google considers YMYL or not, with clear examples. 

Low Quality Pages – Section 6.0Google revamped its definition of what it means to be a low-quality page. In a previous version, Google claimed a page may be low quality, in part, because the creator of the main content may lack sufficient expertise for the purpose of the page. This statement was deleted. Google now expands upon the role of E-A-T in determining whether a page is low-quality in three new paragraphs: 
Google explains that the level of E-A-T required for the page depends entirely on the topic itself and the purpose of the page. Topics that only require everyday expertise don’t require that the content creators provide information about themselves. Google also suggests that a low-quality page can exist on an otherwise authoritative website, like an academic site or a government site. The topic itself of the page is where YMYL comes into play – if the content could potentially cause harm to the user, quality raters must evaluate that aspect when determining the quality of the page. Lacking Expertise, Authoritativeness, or Trustworthiness (E-A-T) – Section 6.1Google added a bullet point in its definition of what it looks like to lack E-A-T when determining whether a page is low-quality:
In another new addition, Google once again repeated that the level of E-A-T a page requires depends on the purpose and the topic of the page. If the page discusses YMYL topics (and potentially presents harm to the user or others), E-A-T is critical. Even if the website has a positive reputation, if there is a significant risk of harm, the page must be rated as low quality. 
Lowest Quality Pages – Section 7.0Google inserted a new section in the “lowest quality pages” section suggesting that even authoritative or expert sources can still present harmful content. This could include hacked content or user-uploaded videos. Just because content exists on a site that otherwise demonstrates good quality, if the content itself is deceptive, harmful, untrustworthy or spam, this still requires a “lowest quality” rating. 
Google’s new document about Search Quality Rater GuidelinesIn addition to updating the Search Quality Rater Guidelines, Google also published a new resource describing how the Search Quality Rater Guidelines work. This resource includes sections about how search works, improving search and the quality rating process. This document provides the most comprehensive overview to date of the role Google’s quality raters play in evaluating how well Google’s proposed changes are in line with Google’s own quality guidelines. Google also provides information about who the raters are, where they are located and how the rating process works. Why these changes matterFor those interested in understanding how Google defines the concepts of YMYL and E-A-T, Google’s updated Quality Rater Guidelines provide some new guidance about what they aim to achieve with their algorithm. As opposed to thinking about YMYL in terms of business or content categories, Google asks raters to think about the extent to which content can cause harm to users. Google also clarified that everyday expertise is sufficient for many types of content, but E-A-T is of the utmost importance when the content qualifies as YMYL (it has the potential to cause harm to individuals or society, or can affect one’s financial wellbeing, health or safety). The post Google search quality rater guidelines update: What has changed appeared first on Search Engine Land. via Search Engine Land https://ift.tt/yBi6NCc Neeva has revealed how it instructs human evaluators to rate its search results, specifically for technical queries. Like Google (which, coincidentally, updated their quality rater guidelines today), Neeva uses human raters to assess the quality of its search results. The guidelines break down into three key areas: query understanding, page quality rating and page match rating. Query understanding. This is all about figuring out the intent behind the user’s search query. Neeva breaks down the types of queries into the following categories:
Page quality rating. Neeva has broken down pages into three levels of quality: low, medium and high. Advertising usage, page age and formatting are critical elements. Here’s a look at each: Low quality:
Medium quality:
High quality:
Page match. Neeva has its raters give a score to the match between the query and a webpage, between 1 (significantly poor) to 10 (vital). Here’s that scale:
Read the full guidelines. They were published on the Neeva blog, here. Why we care. It’s always smart to understand how search engines assess the quality of webpages and content, and whether it matches the intent of the search. Yes, Neeva has a tiny fraction of the search market share. But the insights Neeva shared can provide you some additional ways to think about, assess and improve the quality of your content and webpages. The post Neeva shares search rating guidelines for technical queries appeared first on Search Engine Land. via Search Engine Land https://ift.tt/ndB2gfR Google has updated its search quality raters guidelines today, this is an update from the October 2021 update. You can download the full 167-page PDF raters guidelines over here. This version has refreshed language in the new overview section, a refined YMYL section, with more on low-quality content, YMYL, E-A-T, and more. What is new. Google posted these bullet points on what is new on the last page of this PDF.
Why we care. Although search quality evaluators’ ratings do not directly impact rankings (as Google clarified in the document), they do provide feedback that helps Google improve its algorithms. It is important to spend some time looking at what Google changed in this updated version of the document and compare that to last year’s version of the document to see if we can learn more about Google’s intent on what websites and web pages Google prefers to rank. Google made those additions, edits, and deletions for a reason. You can download the 167-page PDF raters guidelines over here. The post Google search quality raters guidelines updated today appeared first on Search Engine Land. via Search Engine Land https://ift.tt/DbcVJUY A writer at work who stands out from their coworkers can always confidently answer the question: What’s it like working... The post 7 Often Overlooked Steps to Be a Better Writer at Work appeared first on Copyblogger. via Copyblogger https://ift.tt/rGXlwix Entity search can be a massive competitive advantage. But you first need to build your entity-based strategy. This article will cover how to create a robust entity-first strategy to help our content and SEO efforts. Most common challenges search and content marketers faceRelevant, topical content, discovery based on customer intent is still the biggest challenge we face as search marketers. Content relevancy, in my mind, means the content is personalized, must tell a story, should be scannable, readable, provides images, and the layout can be consumed on any device. Here are five outcomes we aim to accomplish with content:
The most common struggle we all face is determining what type of content to create or add. Aligning strategies with search enginesSearch engines are evolving and content marketing strategies need to align across all verticals from popularity and quality to the intent behind the query and the overall page experience. Search engine priorities, results, algorithms and needs have evolved over time. 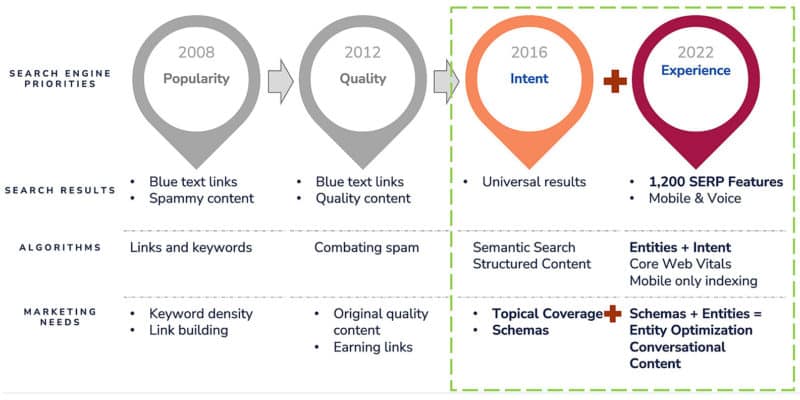
As users search on screenless devices and spoken queries increase, search engines use artificial intelligence and machine learning to try and replicate how humans think, act and react. Search engines must decode a sentence (or paragraph) long query and serve results that best match it. This is where entities come in. Entities are things search engines can understand without any ambiguity independent of language. Even when a website has a wealth of content, search engines need to understand the context behind it, identify the entities within the content, draw connections between them and map them to the query of the searcher. Deploying schemas and marking up the entities within your content gives search engines the context and helps them understand your content better. A convergence of technology and contentContent, where entities are not marked with schemas, tends to underperform. Similarly, deploying schemas on content that does not contain all the relevant entities or does not provide all the information will also not have maximum impact. Entity optimization uses advanced nested schemas deployed on content that meets the searchers’ needs and contains all the relevant topics and entities. Let’s use a live project as an example and show what we accomplished for one of our clients. 8 steps to developing an entity-first strategyWe deployed the eight steps given below as an entity-first-strategy for one of our client in the health care vertical to help them get the best topical coverage and visibility. We started by identifying the most relevant schema in their industry followed by determining the gaps within their content for both schema and entities. 
1. Identified schema vocabularyWe created a list of all applicable schemas in the healthcare industry. 2. Determined the schema gapsWe identified the schema gaps by comparing the current site content against the applicable schemas. 3. Mapping schemaOnce we identified the schema gaps, we identified the most relevant pages to deploy the unused schemas. 4. Market opportunity and potential sizingWe used in-depth keyword research and analysis of current content performance. Map content based on informational, navigational and transactional content. It is critical to see how your current branded and non-branded content is performing and what your focus should be based on business goals. 
We identified the pages that could see the most impact and potential from topic, entity, and schema optimization. 5. Map topic gapsOnce we identified the best potential pages, we cross-referenced the gaps in the content by analyzing the topics and entities covered by other ranking websites. 6. Identify Content OpportunitiesWe enhanced the page architecture by adding relevant content elements, such as images, headings and lists. 
Topic/entity gaps covered:
Schema gaps covered:
7. Content enhancementOptimized the content by incorporating missing topics and entities 8. Create better than the best website pageWe then created the perfect in-depth page, rich with relevant topics the target audience is searching for. Measuring entity strategy ImpactWhen we measured the impact of adding entities and schema into our strategy for this healthcare company, we saw a 66% lift in visibility and inclusions in rich results. 
While the above image is just one example of the impact entities and schema can have, you can see below how many different industries benefit by deploying schema and entity coverage. 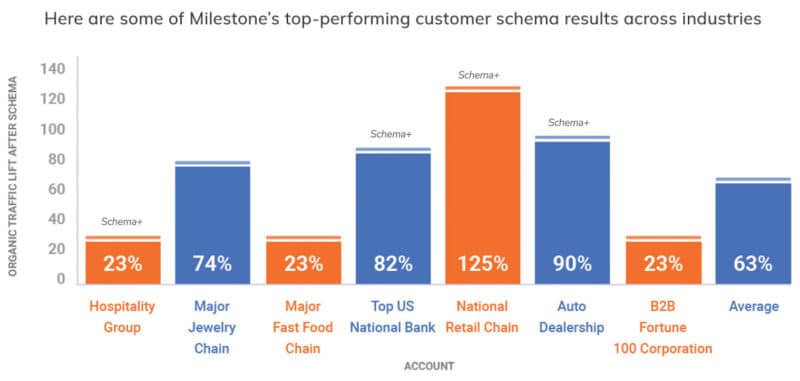
Key takeawaysCreating content is more than writing. It is robust when you add in all the elements from design, development, topical entity coverage and schema. All these elements need to align to give optimum results. Keeping organization in mind, cluster pages of relevant content and connect them through pillar pages, ensuring to take advantage of the interlinking opportunities. Treat each page as the main category page with several relevant pages linked. Adding interlinking helps in discovery and relevancy. Once you have an entity-first strategy for content, you need to think about how to scale the process of:
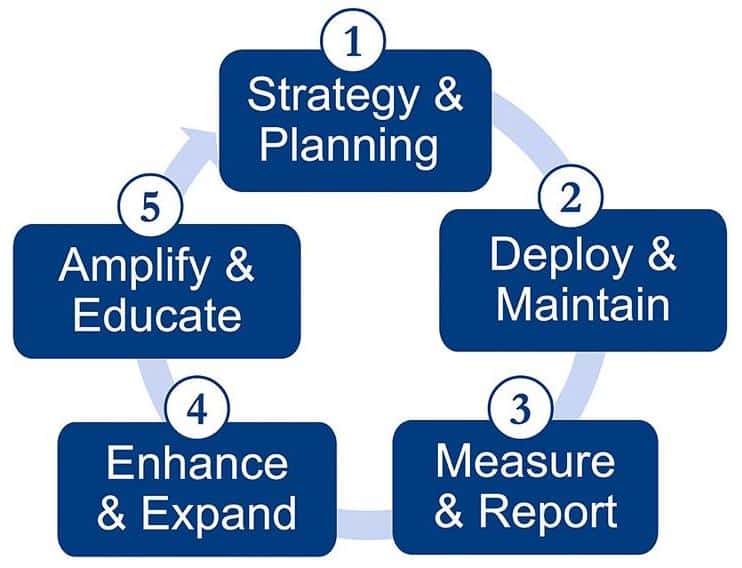
In my next article, we will explore how you can deploy, measure and report performance, enhance where needed and scale your entity-first strategy. The post 8 steps to a successful entity-first strategy for SEO and content appeared first on Search Engine Land. via Search Engine Land https://ift.tt/LaEJt9G |
Archives
April 2024
Categories
|
