INTERNET MARKETING SUCCESS


Google Shopping Ads are a powerful platform for increasing your sales. With Black Friday fast approaching, implementing the latest tactics is crucial to ensure your ad spend is invested wisely amid rising costs per click. These five essential optimizations that will instantly impact your campaigns are brought to you by Google Shopping Feed partner ShoppingIQ, who specializes in overcoming existing limitations of Google Shopping and Performance Max campaigns, whist developing extra features, optimizations and targeting options that are not accessible through the Google Ads or Google Mercant Center interface. Within this guide, Alam Hosseinbor, ecommerce director at ShoppingIQ, unveils a number of “secrets that Google won’t tell you” and emphasizes that “shopping advertisers unknowingly waste thousands of dollars per year without realizing.” Follow the link at the end of this blog post to download the full list of tips and access your free one-hour consultation for more bespoke advice and tactics. The below five optimizations are critical and we strongly suggest they are reviewerd and implemented ASAP. 1. Real-time feed stock updatesA shocking fact: for more than 95% of ecommerce brands, even after their products go out of stock, their product ads stay active on Google Shopping for 12 to 24 hours, and in some cases longer. This leads to unnecessary CPC charges, reduced ROI and frustrates customers when they arrive at pages with out-of-stock items. While this not only drains your budget, it also leads to product disapprovals due to incorrect stock status. Furthermore, as your best-selling items are most likely to go out of stock, this adversely affects the bidding algorithm as Google’s latest signals perceive these products as live but unproductive, pushing them down the priority list when they are back in stock. Take a look at this video, which serves as an example of how Argos, a prominent U.K. retailer, was unintentionally wasting its advertising budget on products that were out of stock during its Black Friday campaign when CPC rates were already soaring due to heightened competition. In the video, you can witness an active ad directing a user to the relevant landing page, only to discover that the product they clicked on is no longer available. This negatively impacts the budget and provides a suboptimal customer experience from a branding and technological perspective. So, what’s the solution to this problem? If you rely on Google Sheets, FTP or XML links to manage your feeds in Google Merchant Center, there’s a higher likelihood that you’re facing this issue, although it’s not exclusive to these file formats. ShoppingIQ has developed a unique, real-time proprietary stock updating technology, and leveraging this technology is essential. It prevents unnecessary ad spend on out-of-stock items, particularly during inflated CPC rates, safeguarding your budget and ensuring efficient expenditure throughout the year, especially during peak seasons when CPCs are at their highest. 2. Real-time feed price updatesReal-time stock updates are important, but the same goes for pricing. Delays in getting your price drops to market also slow down your revenue potential during sale periods. For instance, during a sale, you would want to capitalize on the increased click-through rates (CTR) and sales that price drops provide immediately, not on your next feed update, typically the next day. This issue becomes especially critical during limited-time events such as Black Friday or weekend sales. In the same video as above, where you saw Argos paying for an out-of-stock click, it follows with the same user experiencing another issue who was forced back to the results pages to choose an alternative shop. This time, Amazon is at fault for promoting an inaccurate price that misleads the customer. In this instance, as the actual website price is higher, it frustrates the customer and lowers the conversion rate due to the deceptive pricing information. It is highly recommended to maximize performance and efficiency by having the ability to reflect and adjust your product prices in your live ads in real-time, harnessing market changes and tactical opportunities. This feature proves invaluable for businesses frequently running sales or promotions, as it guarantees that your ads reflect the most up-to-date pricing information. While this also reduces product disapproval, keeping your prices correct and maximizing the revenue from price drops as they happen is essential. 3. Incremental converting keyword insights and keyword targetingIn a landscape where Google and Performance Max campaigns are reducing insight and optimization control, ShoppingIQ puts control back in the hands of advertisers. It allows precise control over your products’ appearance in Google Shopping search results. You can target your ads using a range of keywords, including product names, brand names and product attributes. This precision ensures that your ads reach potential buyers with the highest intent. Importantly, converting keyword insights at the product level are provided even for Performance Max campaigns, and such data is certainly not available via the Google Ads interface. This strategy includes providing brands with additional data to support product feed title, description optimization and incremental keyword targeting. 4. 20% CPC discountA Google CSS partner like ShoppingIQ offers a permanent discount on your Google Shopping spend. This discount is applied to your account and gives your shopping campaigns 20% more bidding power without extra charges. As a result, your cost per click will end up being cheaper. For example, reducing your bids by 20% will be equivalent to the same bid you had before. Therefore, this discount will quickly reduce advertising costs and enhance your ROI. It’s a straightforward process with no need for alterations to your existing ad campaigns. Please note that this discount is only available for ad campaigns running activities in the U.K. or EU. This discount was mandated for Google by EU courts due to anti-competitive reasons and to acknowledge the contributions of Google feed partners in helping brands grow their online shopping spends on Google. We highly recommend that you opt for this discount, as Google is unlikely to inform you about it. 5. Free competitor trackingShoppingIQ goes a step further by providing free competitor tracking. This feature lets you compare your products with your competitors regarding price, availability and impression share in Google Shopping search results. This invaluable data enables you to identify areas for campaign improvement and stay ahead of the competition. Additionally, you can dynamically adjust your product offerings based on price competitiveness. Beyond these five core advantages, there are a host of additional features to refine your Google Shopping campaigns: • Advanced reporting and analytics: Gain deep insights into your campaign’s performance to refine your strategies. • Automated bidding: Optimize your bidding strategies to maximize ROI. • Image optimizations: Make your ads visually appealing to stand out. • Product optimization tools: Fine-tune your product listings for better visibility. • Advanced product optimizations: Implement advanced tactics to improve product rankings. In summary, these tips are suitable for businesses of all sizes seeking to enhance their Google Shopping campaign performance. For tips and advice for your brand, we recommend you take advantage of the free 1-hour consultation. You will learn more about the plenty of incremental features not available via the Google Ads interface, and to enhance your performance beyond the limitations of Google Performance Max campaigns. For more comprehensive guidance and additional tips to grow your revenue efficiently and quickly, you can download a free guide from https://shoppingiq.com/learn/free-guide. The post 5 essential Google Shopping optimizations Google won’t tell you appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2RpIBhm
0 Comments
How has it only been 25 years? Am I the only one who feels like there can’t have been a world without Google?! The search and technology behemoth has undoubtedly impacted most human experience across the globe in some form or another, but none more so than for the SEOs of the world. The SEO industry effectively shares its history with Google. Once search engines like Google started to become the primary method through which people accessed information online, it became crucial for businesses to have a digital presence and be listed on search engine results pages (SERPs). Evolution of the algorithm: Changes in SEO focusThanks to ever-evolving algorithms and expectations, search is a relentless journey of adaptation and resilience for SEOs. Each update feels like a new puzzle, urging the industry to delve deeper, understand better and refine strategies to ensure sites continue to shine organically. It’s about trying to anticipate the subtleties of algorithm changes, predicting what will come next and constantly innovating to keep content relevant, user-friendly and, importantly, visible. Every change is a new opportunity to learn. Here are just some of the many algorithm changes that SEO has (mostly) survived, as told by industry veterans themselves. Penguin updateWhen we talk about Google shaking things up in the SEO world, the Penguin update of April 2012 is one for the books. It was the kind of wave that reshaped how we all thought about links and rankings and made us rethink our game plans. Mark Williams-Cook, co-owner of search agency Candour, has some pretty vivid memories about this time. “The April 2012 Penguin v1 Update… it made such profound and lasting changes in the industry,” he said. Before Penguin rolled out, the more, the merrier was the mantra regarding links. It was all about piling on those links, and aggressive link building was the way to go. There were places where you could buy links, and services promising to boost your rankings actually worked! But then, Penguin happened. It was like a switch flipped overnight. Williams-Cook saw it all – big names in affiliate marketing saw their traffic go down the drain, agencies were getting the boot from clients whose rankings tanked, and suddenly, folks were charging money to remove links. Major web players like Expedia didn’t escape the penalties either. He shares his own brush with Penguin quite candidly. “I personally had a few of my money websites tank (deservedly), and it was a great lesson in ‘it works until it doesn’t’.” It’s a reminder of how strategies that seem to work can suddenly backfire if they aren’t sustainable or authentic. Medic updateLet’s hop back to August 2018, which is likely to be well remembered by many SEO enthusiasts with health-related sites – all thanks to the Medic update. Brady Madden, founder at Evergreen Digital, had a CBD commerce website under his wing. He enjoyed the fruits of ranking well, with sales soaring over $100,000 monthly. Then Medic hit, and it was like the rug was pulled out from under him, leading to a loss of around $50,000 in sales in just a month. “Since this ‘Medic’ update was so new, we didn’t know where or what to address,” Madden said He and his team took about six months to revamp their strategies, reassess their content, strengthen their link building campaigns and make several other crucial adjustments to bounce back. “At the time, I had been around SEO and digital marketing for 5+ years… This whole event really got me going with SEO and has become my top marketing channel to do work for since then,” Madden shares as he reflected on the journey that this update had led him on. Medic was termed a “broad, global, core update” by Google, with a peculiar focus on health, medical, and Your Money Your Life (YMYL) sites. Google’s advice was straightforward yet frustrating for many – there’s no “fix,” just continue building great content and improving user experience. The update was a learning curve and a revelation of SEO rankings’ dynamics and core algorithm updates’ impacts. “I also learned that while they’re tedious to read, docs like Google’s Quality Raters Guidelines provide a wealth of knowledge for SEOs to use,” Madden said, highlighting the invaluable lessons to be learned from Google’s documentation. Diversity updateOlivian-Claudiu Stoica, senior SEO specialist at Wave Studio, has been in the SEO game since 2015. He fondly remembers this transformative update. “The Diversity update from 2019 was a nice touch from Google… This clearly helped smaller sites gain visibility,” Stoica said. The Diversity update ensured a more equitable representation by limiting the presence of the same domain to no more than two listings per search query, striving to bring balance to search results. It was a shift toward a richer, more diverse search experience, offering users a wider array of perspectives and information sources. Stoica also sheds light on the updates that profoundly impact businesses today. He highlights the Helpful Content, Spam, and Medic updates as pivotal changes defining the contemporary SEO landscape. “Holistic marketing, brand reputation, PR-led link building, well-researched content, customer experience, and proven expertise are now the norm to succeed in Google Search,” he said, outlining the multifaceted and often multi-disciplined approach required from modern SEOs. Product reviews update, May 2022 core update and moreAfter Penguin, things didn’t get any smoother, and Ryan Jones, marketing manager at SEOTesting, has quite the tale about rolling with the punches of Google’s relentless period of updates. “The site hovered between 1,000 and 1,500 clicks per day between November 2021 and December 2021,” he shares. But then, it was like a series of rapid-fire updates came crashing down: December 2021 Product Reviews Update, May 2022 Core Update, and more. And the impact? It was like watching the rollercoaster take a steep dive. The traffic went from those nice highs to around 500 clicks per day. “Between half and more than half of the traffic was gone,” Jones said. But it wasn’t just about the numbers but about figuring out where the ship was leaking. Turns out, most of the traffic loss was from the blog. “Google was no longer loving the blog and was not ranking it,” Jones said. It was a wake-up call, leading to some tough decisions, like removing around 75 blog posts – a whopping 65% of the blog. It wasn’t just about cutting the losses but about rebuilding and re-strategizing. Diving deep into content marketing, investing in quality writing, and focusing on truly competitive content became the new game plan. “We also invested in ‘proper’ link building… which we believed helped also,” Jones added. And the journey didn’t end there. The uncertainty and stress continued with the next series of updates, including the July 2022 Product Reviews Update and the October 2022 Spam Update. “It took a while, but we achieved a 100% recovery from this update,” Jones said. Link spam and helpful content updatesJonathan Boshoff, SEO manager at Digital Sisco, recounts the experience of turbulence when algorithms threw curveballs one after the other. “In my previous role, I ran SEO for one of Canada’s largest online payday loan companies. We got hit by three algorithm updates in a row (2022 link spam and helpful content, and one in Feb.) This was the comedown from all-time highs. The company was thrilled to be making lots of money with SEO, but the algorithm updates destroyed all our rankings. Essentially, the whole company was scrambling. Everyone became an SEO all of a sudden.” Boshoff’s story is a snapshot of the collective experiences of the SEO community. The excitement of top rankings. The scramble when they plummet. And the continuous endeavor to decode and master the changing goalposts. “Ultimately, another algorithm update rolled out and fixed everything. Since then they have continued on to have even better results than ever before. It was a very hectic couple of months!” he shares, underscoring the resilience and adaptability that define the spirit of SEO professionals. E-A-T (and later E-E-A-T)When Google was still in its infancy, the core mission was clear and simple: Create the best search experience possible. In an era where links ruled the kingdom of page ranking, SEO enthusiasts explored every nook and cranny to master the game. Enter E-A-T (Expertise, Authoritativeness and Trustworthiness), a concept that’s been in Google’s quality rater guidelines since 2014. It has been a compass guiding the journey of search engine evolution, with the goal of delivering diverse, high-quality, and helpful search results to the users. Helene Jelenc, SEO consultant at Flow SEO, who was then exploring the realms of SEO with her travel blog, shares her journey and reflections on the inception of E-A-T. “When EAT was added to the guidelines, that’s when things began to ‘click’ with SEO for me,” she said. Jelenc, like many content creators, was striving to offer unique and original content and insights. Her determination to produce well-researched blog posts finally earned recognition and reward from Google. E-A-T isn’t just about the visible and tangible elements like backlinks and anchor text; it’s about building genuine high-level E-A-T, a journey that requires time, effort and authenticity. Google values quality, relevance and originality over quick fixes and instant gains. It’s about promoting the “very best” and ensuring that they get the spotlight they deserve. It’s important to understand that E-A-T and the Quality Rater Guidelines are not technically part of Google’s algorithms. However, they represent the aspirations of where Google wants the search algorithm to go. They don’t reveal the intricacies of how the algorithm ranks results but illuminate its aims. By adhering to E-A-T principles, content creators have a better chance of ranking well, and users get the right advice. Jelenc’s insights and experiences mirror the broader evolution in the SEO world. In an era riddled with misinformation, especially in areas impacting Your Money or Your Life (YMYL) queries, the principles of E-A-T have become more important than ever. “Our humanness and the experiences we have inform our content and add layers that make it unique,” she reflects. Jelenc sees the advancements in E-A-T and the introduction of E-E-A-T (the added “E” being Experience) as steps toward acknowledging the value of human experiences in content creation. With this, she’s optimistic about Google’s future directions “[I]n light of AI-generated everything, Google dropped E-E-A-T, which, in my opinion, is the single most important update in years.” Legacy SEO strategies and tactics: It works until it doesn’tExact match domainsA pivotal moment in Google Search’s history was the devaluation of exact match domains (EMDs). This move reshaped domain strategies and brought a renewed focus on content relevance and quality. Daniel Foley, SEO evangelist and director at Assertive Media, shared a memorable encounter that perfectly encapsulates the significance of this shift. “One of my most memorable moments in SEO was when Matt Cutts announced the devaluation of exact match domains,” he said. The timing of this announcement was awkward for Foley. He had just secured a number one ranking on Google for an EMD he had purchased, using “free for all” reciprocal links and a page filled with nothing but Lorem Ipsum content! His sharing of this achievement with then-Googler Matt Cutts on Twitter didn’t earn applause but instead highlighted the loopholes the devaluation aimed to address. “He wasn’t impressed,” Foley said, recounting how the interaction went “semi-viral at the time.” This anecdote is more than just a glimpse into the cat-and-mouse game between SEO professionals and Google’s updates. It reflects the continual evolution of SEO strategies in response to Google’s quest for relevance and quality. The devaluation of EMDs was a clear message from Google – relevance and quality of content are paramount, and shortcuts to high rankings are fleeting. Backlink profile manipulationSEO is a wild ride. Sometimes, you can’t help but look at some tactics and just – laugh. Preeti Gupta, founder at Packted.com, has some thoughts on this, especially when it comes to old-school strategies like profile creation and social bookmarking. “While there are a bunch of outdated things SEOs do, the most fascinating one to me definitely has to be profile creation, social bookmarking, and things like that,” she said. It’s a funny thing, really. Agencies and SEO folks put in so much time and effort to build these links, thinking it’s the golden ticket. “Agencies and SEOs waste a lot of their time and resources to build these links and I guess this clears the path for genuine sites," Gupta said. "It’s both funny and sad at the same time.” This became even more amusing when the December 2022 link spam update rolled out. It pretty much neutralized the impact of this type of link building. And the irony? The same folks offering these services were now offering to disavow them! Negative SEOLet’s jump back to 2015 with Ruti Dadash, founder at Imperial Rank SEO, who was just dipping her toes into SEO at the time. “What does SEO stand for?” That was her, a complete newbie at a startup, a small fish in a pond teeming with gigantic, well-established competitors with bottomless marketing budgets. SEO became a secret weapon, helping her rank against the giants. Dadash shares a vivid memory of waking up one day to find that rankings had skyrocketed. Detective work revealed a sneaky move from a rival, thousands of backlinks pointing straight to Dadash’s site. But this sudden gift was a Trojan horse as all these links were from sketchy gambling and adult sites, a disaster waiting to happen. “The scramble to put together a new disavow file, and the relief/disappointment as we lost that sudden surge…” You can imagine how this experience shaped her SEO career. “It’s been a wild ride, from watching how Google has evolved to moving from in-house SEO to freelance, and then to founding my own agency,” Dadash said. This wild, unpredictable journey makes SEO such a fascinating field, a constant game of cat and mouse with Google’s ever-evolving algorithms. Hidden textThere was a time when the “coolest” SEO trick in the book was like a magic act – now you see it, now you don’t. Brett Heyns, a freelance SEO, can't help but reminisce about those days. “All time best was white text on a white background, filling all the white space with keywords. Boggles the mind that there was a time that this used to work and was ‘standard practice’!” Heyns said. Hidden text was the stealthy ninja of old-school SEO strategies. In the times when search engines were more like text-matching machines, SEOs could publish one content piece for site visitors and hide another for search engines. Yes, you heard it right! Web pages were stuffed with invisible keywords, creating long, invisible essays, all in the name of ranking. Heyns’s memory of this practice takes us back to when consumers would see a conversion-optimized webpage, blissfully unaware of the keyword-stuffed content hidden behind the scenes. SEOs would ingeniously position white text on white backgrounds or even place images over the text, keeping it concealed from the human eye but visible to the search engine’s gaze. Some even explored more sophisticated schemes, like cloaking, where scripts would identify whether a site visitor was a search engine or a human, serving different pages accordingly. It was like a clandestine operation, showing keyword-optimized pages to search engines while hiding them from users. These techniques might sound like relics from the past. Still, they’re a reminder of the evolution of SEO strategies – from the overtly stealthy to the authentically user-centered approaches we value today. Content scraping and cloningIn the Wild West days of the early internet, SEO was more of an arcane art and less of a science, and it was fertile ground for some pretty wild tactics. Sandy Rowley, SEO professional and web designer, reminisces about a time when the rules were, well, there weren’t really any rules. “Back in the '90s, an SEO expert could clone a high traffic website like CNN, and outrank every one of its pages in a week.” Yes, you heard that right – cloning entire high-traffic websites! This practice, known as scraping, involved using automated scripts to copy all the content from a website, with intentions ranging from stealing content to completely replicating the victim’s site. It's a prime example of black hat SEO tactics where the cloned sites would appear in search results instead of the original ones, exploiting Google’s ranking algorithms by sending fake organic traffic and modifying internal backlinks. This advanced form of content theft wasn’t just about plagiarism. It was about manipulating search engine results and siphoning off the web traffic and, by extension, the ad revenue and conversions from the original sites. It was a tactic that threw fairness and ethical considerations to the wind, leveraging the loopholes in search engine algorithms to gain a competitive advantage. New features, plus ones we loved and lostSeasoned SEOs will all remember (and shed a tear for) at least one tool or feature that has become no more than a relic. Equally, each will have a story about a new innovation or tactic that they’ve had to quickly comprehend. Let’s continue our journey through the anecdotes and rifle through Google’s figurative trash can while finding interesting tidbits about current search attributes. Remember Orkut?Let’s take a nostalgic stroll down memory lane, back to the days of Orkut with Alpana Chand, a freelance SEO. Ah, Orkut. Remember it? It was one of the first of its kind, a social media platform even before the era of Facebook, named after its creator, Orkut Büyükkökten. Orkut was a hub of innovation and connection, especially popular in Brazil and India, offering unique features like customizing themes, having “crush lists,” and even rating your friends. 
“I remember Orkut. I used it when I was in engineering college,” Chand said, recalling the days of shared weak Wi-Fi in dorm rooms and big, heavy IBM computers. Chand paints a picture of when being hooked to Orkut was the norm. “Addicted is understating our obsession,” she said. And let’s not forget those Yahoo forwards filled with quotable quotes shared on Orkut. Seeing your wall and the new feed popping on it was a different vibe. “Today's social media features change in the blink of an eye and Orkut's slow stable feature – the wall, the scrapbook, the direct messages were etched on my mind,” Chand shares. But, like all good things, Orkut had its sunset moment. As platforms like Facebook offered more simplicity, reliability, and innovative features like a self-updating News Feed, Orkut struggled to keep up with its increasing complexity and limited user range. Eventually, Google shifted its focus to newer ventures, like Google+, and in 2014, it was time to bid Orkut farewell. “So many memories and an entire memorabilia was buried along with Orkut's discontinuation,” she said, wishing for some saved screenshots of those times. Hello, featured snippets!Who doesn’t love a quick answer? That’s what Google’s featured snippets aimed to do, and have done for years now. Featured snippets, those handy blocks of content directly answering our queries at the top of SERPS, made their grand entrance in January 2014, much to the dismay of SEOs that relied on traffic for even the shortest answers. They quickly became known as Google’s “answer boxes” or “quick answers,” pulling the most relevant information from web pages and placing it right at the top of our search results. Megan Dominion, a freelance SEO, remembers the early days of Featured Snippets and the missteps that followed. “I remember when the below featured snippets were being spoken about in the SEO industry as well as outside of it,” she said, reminiscing about the time Google got it hilariously wrong. Just imagine searching for “How many legs does a horse have?” and being told they have six! 
“There's a nice spike in search trends for when it happened to commemorate the occasion and the beginning of ‘Google is not always right’,” Dominion points out. 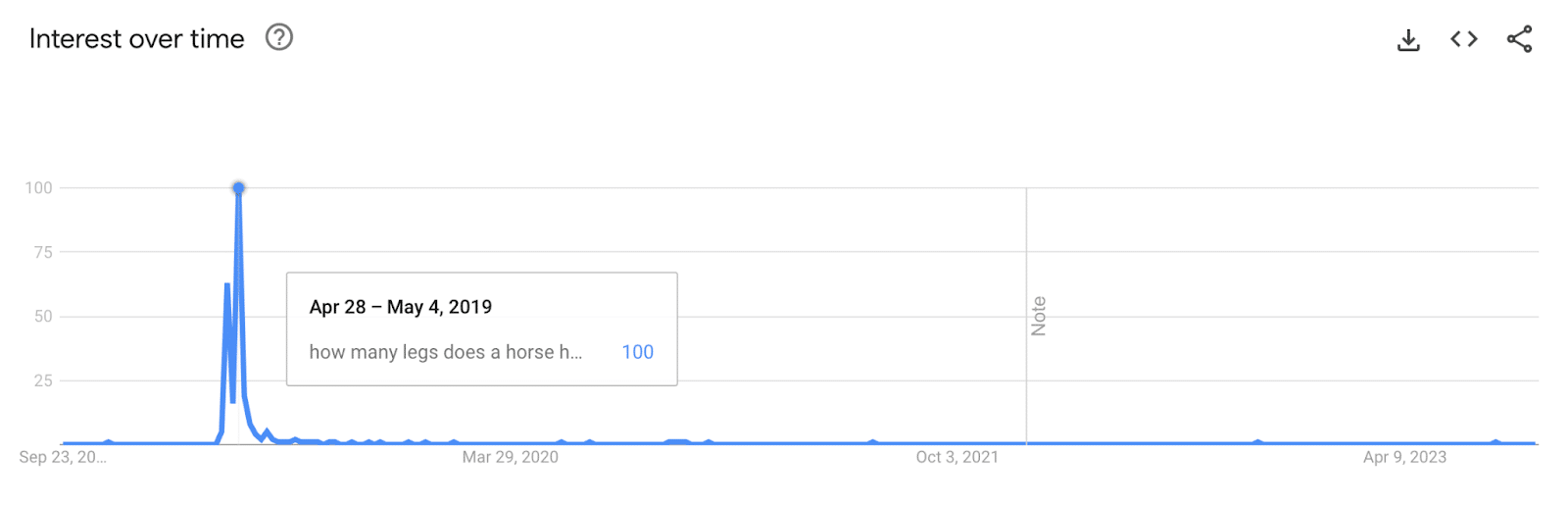
It was a reminder that even the ‘big dogs’ can have their off days. If you fancy a bit of a giggle, check out some more examples of Google’s featured snippets getting it wrong. Featured snippets, with their prominence and direct answers, became a coveted spot for SEOs and website owners, sparking discussions, strategies, and a slew of articles on optimizing for them. They were officially named “featured snippets” in 2016, distinguishing them from short answers pulled from Google’s database. Hreflang havocHreflangs, introduced in 2011, are like signposts for Google’s bots, telling them what language and region a page is intended for. They help avoid duplicate content issues when creating content that’s essentially the same but for different markets. When they work, it’s smooth sailing, but when they decide to go off-script, the outcome can be hilarious. Nadia Mojahed, international SEO consultant at SEO Transformer, had a front-row seat to when hreflang attributes decided to have a bit of fun. Mohajed recalls when a frantic call revealed an ecommerce site in chaos. This site, which had been doing great globally, was suddenly offering luxury handbags like gourmet dishes. It’s all thanks to some cheeky hreflang tags. “Imagine Italian pages talking about pasta and French ones describing sneakers as delicacies!” she laughs. Google turned page titles and descriptions into hilarious misinterpretations. Think “Women's Fashion” in Spanish being read as “Exotic World of Llamas and Ponchos,” and German "Men's Accessories" transforming into “Bratwurst-Tasting Bow Ties.” Getting hreflang attributes right can be a bit of a puzzle, especially for mega-sites with tons of pages. A 2023 study by fellow SEO Dan Taylor even found that 31% of international sites were getting tangled up in hreflang errors. Mojahed quickly found and fixed the issues, turning the blunder into a learning moment about the quirky challenges of SEO tech. Next, please! The rel=prev/next dramaRemember the collective gasp in the SEO community when Google dropped the bomb about rel=prev/next for pagination? Yeah, that was a moment. Lidia Infante, senior SEO manager at Sanity.io, paints the picture vividly. “The time Google announced that they hadn't been using rel=prev/next for a while! There was a range of reactions. From freaking out over how to handle pagination now to mourning all the developer hours we sank into managing it through rel=prev/next.” It turns out this signal had been deprecated for some time before the SEO world was in the know. Infante and many others soon learned that it had other purposes beyond indexing, and well, Google isn’t the only player in the game. Other search engines were still using it. It was a reminder moment for many, understanding that Google was not the only search engine they were optimizing for. This revelation came just before a BrightonSEO edition, and the atmosphere was charged when John Mueller was asked about it on stage during the keynote. “It was a whole vibe,” Infante reminisces. Realizing the mix-up, Google apologized for not proactively communicating this change. They assured they’d aim for better communication about such changes in the future, stating: “As our systems improve over time, there may be instances where specific types of markup are not as critical as it once was, and we’re committed to providing guidance when changes are made.” Oops! Google+ or else?!You’ll be hard-pushed to find an SEO who doesn’t remember Google+ unless they’re super green. Reflecting on its turbulent journey, Mersudin Forbes, portfolio SEO and agency advisor, shares, “Google+ was a flash-in-the-pan, social media platform pushed on us by Google. So much so that they appended the +1 functionality in search results to make us believe that upvoting the search results increased rankings.” Google+ emerged with a promise, a beacon of new social media interaction backed by Google’s colossal influence. Forbes recalls how Google firmly asserted that this feature would be a new signal in determining page relevance and ranking. “This was the start of spammageddon of +1 farming and just as quick as it arrived, it was gone,” he remarks. The bold venture seemed promising, with innovative features like Circles and Hangouts and rapid user acquisition, reaching 90 million by the end of the launch year. However, the spammy notifications and the platform’s failure to maintain active user engagement led to its eventual demise. “I wonder if the same will happen to SGE, one can only hope,” Forbes said. Google+ now stands as a reminder of the transient nature of tech innovations, even those stamped with the Google seal. UA who? The reluctant adoption of GA4When Google Analytics 4 (GA4) debuted, it wasn’t exactly met with a standing ovation from marketers. It was more like a hesitant applause, with some even hosting metaphorical funerals for its predecessor, Universal Analytics (UA). Yes, it was that dramatic! Irina Serdyukovskaya, an SEO and analytical consultant, found a silver lining in the upheaval while grappling with the new intricacies of GA4. “The first months with this were tough,” she admits. But delving into the unknown of GA4 opened up new career paths and opportunities for her. “After solving GA4 tracking questions within the SEO field, I started offering this as a separate service and found myself enjoying learning new tools and understanding the data better.” Serdyukovskaya’s journey resonates with many who initially struggled but eventually found potential growth in adapting to the new system. “Changes are hard, and we get used to the way things are, but this can also be an opportunity to grow professionally,” she reflects. The collective groan about another change in the digital world symbolizes both resistance to change and a concealed desire for novelty and learning. Despite the reluctant adoption and the initial hiccups, the majority eventually boarded the GA4 train, with more than 90% of marketers making the transition, albeit with varying levels of readiness and acceptance. It wasn’t just a switch but a complete migration to a new platform built from scratch, requiring strategic planning and expert implementation. GA4 wasn’t merely a new “version.” It was a paradigm shift in how data was collected, processed, and reported. And with Google sunsetting UA, the reluctant adaptation became necessary, pushing many to leave the comfort of the familiar and step into the unknown, just like Irina did. Reflections and looking forwardThat’s a wrap on 25 years – a trip down memory lane with the seasoned SEO pros who've been through the thick and thin of Google's ever-evolving world. We’ve dived deep into the archives, laughed over the old wild days, and scratched our heads over the relentless changes and updates we’ve all seen and felt. Huge thanks to all the SEO pros who chipped in with their tales, insights, and lessons for this article. Your shared experiences give us all a closer, more colorful look at the twists and turns that have made the world of SEO what it is today. It’s been a wild ride, and it’s awesome to hear about it from the folks who’ve lived it! So, what about the next 25 years?Will AI and Search Generative Experience (SGE) revolutionize how we search and measure SEO success? Will SEO undergo drastic transformations, or heaven forbid, will it finally die as has been foretold many times? Or, in a plot twist, will we all just surrender and switch allegiances to Bing? It’s a fascinating future to contemplate – a future where the integration of AI could reshape our interaction with online spaces, making searches more intuitive, personalized, and responsive. SGE could redefine user engagement, creating more immersive and dynamic experiences. Will we still be chasing algorithms, or will the advancements enable a more harmonious coexistence where the user experience is paramount? SEO is more about enhancing this experience than outsmarting the system. Whatever the future holds, here’s to embracing the challenges, exploring new frontiers, and navigating another 25 years of dancing with Google. Happy 25th, Google! Keep those surprises coming, and keep us guessing! The post Google Search at 25: SEO experts share memorable moments appeared first on Search Engine Land. via Search Engine Land https://ift.tt/GuecZ0q Google stunned the PPC community after openly admitting to quietly adjusting ad prices to meet targets. The confession comes eight years after Google Ad executive Jerry Dischler denied the search engine manipulates ad auctions at SMX Advanced in 2015. The backtracking has infuriated digital marker Gregg Finn – so much so that he now believes advertisers should consider leaving Google. But will others follow? Here’s a recap of Greg’s comments from the Marketing O’Clock podcast. Google has lost all trust and credibility
Stop calling it an auction


Stop lying
Google’s terminology is ‘misleading at best’
RGSP is ‘ridiculous’
People should leave!
Deep dive. Read our Google antitrust trial updates for all the latest developments from the federal trial. The post Has Google Ads lost all credibility? Why one advertiser says it’s time to leave appeared first on Search Engine Land. via Search Engine Land https://ift.tt/fOJbt21 Google will soon block Bard’s shared conversations from appearing in Google Search. Google Bard recently came out with shared conversations that let users publicly share the chats they had with Bard. Soon after Google Search started to discover those URLs, crawl them, and index them. The issue. Gagan Ghotra posted on X a screenshot showing how a site command for site:bard.google.com/share returned results from Bard. Those results were shared conversations. Here is a screenshot of Bard showing up in the Google Search index: 
Google will block Bard results from Google Search. I asked Google’s Search Liason, Danny Sullivan, about this and he responded on X saying, “Bard allows people to share chats, if they choose. We also don’t intend for these shared chats to be indexed by Google Search. We’re working on blocking them from being indexed now.” Google will soon remove Bard’s shared conversations from showing in Google Search. Why we care. So if you see Bard’s shared conversations showing up in Google Search, don’t fret it, they should go away in the coming days. Google said it does not want them to show up in Google Search’s index and they are working on blocking them now. The post Google to block Bard’s shared chats from showing in Google Search appeared first on Search Engine Land. via Search Engine Land https://ift.tt/Y7BvmF1 Facebook can be sued over claims its advertising algorithm is biased, a California State Court of Appeals has ruled. The decision reverses a previous ruling from 2020 that stated Facebook was protected from accountability under Section 230 – a law that shields online platforms from legal action when users share illegal material. Why we care. Brands utilizing Facebook’s ad tools may unintentionally be engaging in discriminatory practices if the platform’s algorithm is found to be biased. Biased ad algorithm? Facebook was originally taken to court in 2020 for violating civil rights laws. The social platform was accused of not showing insurance ads to women and older people after 48-year-old Samantha Liapes tried to use Facebook to find an insurance provider. Liapes claimed she wasn’t shown insurance ads due to her age and gender. 2020 outcome. The case was originally dismissed by the court after it found Facebook’s tools “neutral on their face and concluding that Facebook was immune under the Communications Decency Act, 47 U.S.C. 230.” However, Liapes appealed the decision. Appeal. The decision was reversed on 21 September 2023 after the appeals court found that the case "adequately" alleges that Facebook “knew insurance advertisers intentionally targeted its ads based on users’ age and gender" – which is in violation of the Civil Rights Act. The court concluded: "Facebook does not merely proliferate and disseminate content as a publisher ... it creates, shapes, or develops content" with the tools. Deep dive. Read the Liapes v. Facebook, Inc. case in full for more information. The post Facebook can be sued over biased ad algorithm claims, court rules appeared first on Search Engine Land. via Search Engine Land https://ift.tt/m1gaWzc Apple is not planning to create its own search engine to rival Google. Eddy Cue, Apple’s Senior Vice President of Services, is expected to testify at the federal antitrust trial that there are no plans for an “Apple Search” model because its partnership with Google works better for its customers, reports Bloomberg. Cue notably helped negotiate Apple’s multibillion-dollar deal with Google, which took four months “working every single day” to finalize. Why we care. The U.S. Justice Department argues that Google’s deal with Apple to become the default search engine on its products has played a major role in creating an unfair search landscape as it’s prevented rival search engines from being able to compete seriously. The testimony from Cue, which Apple tried to block per Reuters, provides a significant insight into Google’s relationship with Apple. Apple’s deal with Google. Google has a financial agreement in place with brands like Apple to be the default search engine on its products at a cost of around $10 billion a year. In addition, Google pays Apple advertising revenue – which is one of the search engine’s biggest costs. Apple reports its income from Google as advertising revenue, which is categorized under its services division. This amounted to $78.1 billion in sales during Apple’s fiscal year 2022. Google could pay Apple as much as $19 billion this fiscal year, according to an estimate from Bernstein analyst Toni Sacconaghi. Why Google is Apple’s default search engine. Cue is expected to testify that Apple chose Google as the default search engine for its product because it is the best search engine. He will also state that Apple has financial deals with other search engines such as Yahoo, Microsoft Bing, DuckDuckGo and Ecosia, as well as Google. In addition, Cue is set to claim that Apple customers with Google as their default search engine can easily change it, echoing comments made by Google’s lawyer, John Schmidtlein. However, DuckDuckGo founder and CEO Gabriel Weinberg told the court last week that changing a default search engine is “way harder than it needs to be.” He said:
Who else has testified? Cue will be the scond executive from Apple to testify, following pple AI head (and former Google executive) John Giannandrea last week. However, the majority of Giannandrea’s testimony was given in a closed courtroom and so the details and not publicly available. What has Google said? John Schmidtlein, lead lawyer for Google, claims the company dominates the search market with a 90% share because it is a superior product – not because it has financial deals that give its rivals an unfair advantage. In contrast, it highlights the default inclusion of Microsoft's Bing on the Windows operating system, which has not significantly helped Bing's market position. Deep dive. Read our Google antitrust trial updates for all the latest developments in this landmark case. The post Apple has 19 billion reasons not to build a Google Search rival appeared first on Search Engine Land. via Search Engine Land https://ift.tt/V6UHylc Microsoft Advertising Network for retail has been rolled out in the US. The network has been designed to simplify the process of creating retail media campaigns, making it easier for brands to launch their retail media programs faster by:
Microsoft has not yet confirmed when the network will be expanded to additional markets. Why we care. Creating a retail media program is typically time-consuming and resource-intensive, involving multiple teams and can take a long time to become profitable. The Microsoft Advertising Network for retail streamlines this process, enabling retailers to launch profitable programs quickly and access relevant advertiser budgets from Microsoft Advertising’s extensive network. What is Microsoft Advertising Network for retail? Microsoft Advertising Network for Retail is a new program that lets advertisers use Microsoft’s wide-reaching ad resources and access high-intent shoppers to boost their business. By joining the network, you can potentially increase sales and retail media revenue with quality ads, even if you have a private retail media platform. What has Microsoft said? Paul Longo, Global Head of Retail Media Sales at Microsoft, said in a statement:
Deep dive. Read the Microsoft Advertising blog for more information. The post Microsoft Advertising Network for retail launches in the US appeared first on Search Engine Land. via Search Engine Land https://ift.tt/FKPAl12 Generative AI, a subset of artificial intelligence, has emerged as a revolutionary force in the tech world. But what exactly is it? And why is it gaining so much attention? This in-depth guide will dive into how generative AI models work, what they can and can’t do, and the implications of all these elements. What is generative AI?Generative AI, or genAI, refers to systems that can generate new content, be it text, images, music, or even videos. Traditionally, AI/ML meant three things: supervised, unsupervised, and reinforcement learning. Each gives insights based on clustering output. Non-generative AI models make calculations based on input (like classifying an image or translating a sentence). In contrast, generative models produce “new” outputs such as writing essays, composing music, designing graphics, and even creating realistic human faces that don’t exist in the real world. The implications of generative AIThe rise of generative AI has significant implications. With the ability to generate content, industries like entertainment, design, and journalism are witnessing a paradigm shift. For instance, news agencies can use AI to draft reports, while designers can get AI-assisted suggestions for graphics. AI can generate hundreds of ad slogans in seconds – whether or not those options are good or not is another matter. Generative AI can produce tailored content for individual users. Think of something like a music app that composes a unique song based on your mood or a news app that drafts articles on topics you’re interested in. The issue is that as AI plays a more integral role in content creation, questions about authenticity, copyright, and the value of human creativity become more prevalent. How does generative AI work?Generative AI, at its core, is about predicting the next piece of data in a sequence, whether that’s the next word in a sentence or the next pixel in an image. Let’s break down how this is achieved. Statistical modelsStatistical models are the backbone of most AI systems. They use mathematical equations to represent the relationship between different variables. For generative AI, models are trained to recognize patterns in data and then use these patterns to generate new, similar data. If a model is trained on English sentences, it learns the statistical likelihood of one word following another, allowing it to generate coherent sentences. 
Data gatheringBoth the quality and quantity of data are crucial. Generative models are trained on vast datasets to understand patterns. For a language model, this might mean ingesting billions of words from books, websites, and other texts. For an image model, it could mean analyzing millions of images. The more diverse and comprehensive the training data, the better the model will generate diverse outputs. How transformers and attention workTransformers are a type of neural network architecture introduced in a 2017 paper titled “Attention Is All You Need” by Vaswani et al. They have since become the foundation for most state-of-the-art language models. ChatGPT wouldn’t work without transformers. The “attention” mechanism allows the model to focus on different parts of the input data, much like how humans pay attention to specific words when understanding a sentence. This mechanism lets the model decide which parts of the input are relevant for a given task, making it highly flexible and powerful. The code below is a fundamental breakdown of transformer mechanisms, explaining each piece in plain English.
In code, you might have a Transformer class and a single TransformerLayer class. This is like having a blueprint for a floor vs. an entire building. This TransformerLayer piece of code shows you how specific components, like multi-head attention and specific arrangements, work. 
A feed-forward neural network is one of the simplest types of artificial neural networks. It consists of an input layer, one or more hidden layers, and an output layer. The data flows in one direction – from the input layer, through the hidden layers, and to the output layer. There are no loops or cycles in the network. In the context of the transformer architecture, the feed-forward neural network is used after the attention mechanism in each layer. It’s a simple two-layered linear transformation with a ReLU activation in between.
How generative AI works – in simple termsThink of generative AI as rolling a weighted dice. The training data determine the weights (or probabilities). If the dice represents the next word in a sentence, a word often following the current word in the training data will have a higher weight. So, “sky” might follow “blue” more often than “banana”. When the AI “rolls the dice” to generate content, it’s more likely to choose statistically more probable sequences based on its training. So, how can LLMs generate content that “seems” original? Let’s take a fake listicle – the “best Eid al-Fitr gifts for content marketers” – and walk through how an LLM can generate this list by combining textual cues from documents about gifts, Eid, and content marketers. Before processing, the text is broken down into smaller pieces called “tokens.” These tokens can be as short as one character or as long as one word. Example: “Eid al-Fitr is a celebration” becomes [“Eid”, “al-Fitr”, “is”, “a”, “celebration”]. This allows the model to work with manageable chunks of text and understand the structure of sentences. Each token is then converted into a vector (a list of numbers) using embeddings. These vectors capture the meaning and context of each word. Positional encoding adds information to each word vector about its position in the sentence, ensuring the model doesn’t lose this order information. Then we use an attention mechanism: this allows the model to focus on different parts of the input text when generating an output. If you remember BERT, this is what was so exciting to Googlers about BERT. If our model has seen texts about “gifts” and knows that people give gifts during celebrations, and it has also seen texts about “Eid al-Fitr” being a significant celebration, it will pay “attention” to these connections. Similarly, if it has seen texts about “content marketers” needing specific tools or resources, it can connect the idea of “gifts” to “content marketers“. 
Now we can combine contexts: As the model processes the input text through multiple Transformer layers, it combines the contexts it has learned. So, even if the original texts never mentioned “Eid al-Fitr gifts for content marketers,” the model can bring together the concepts of “Eid al-Fitr,” “gifts,” and “content marketers” to generate this content. This is because it has learned the broader contexts around each of these terms. After processing the input through the attention mechanism and the feed-forward networks in each Transformer layer, the model produces a probability distribution over its vocabulary for the next word in the sequence. It might think that after words like “best” and “Eid al-Fitr,” the word “gifts” has a high probability of coming next. Similarly, it might associate “gifts” with potential recipients like “content marketers.” How large language models are builtThe journey from a basic transformer model to a sophisticated large language model (LLM) like GPT-3 or BERT involves scaling up and refining various components. Here's a step-by-step breakdown: LLMs are trained on vast amounts of text data. It’s hard to explain how vast this data is. The C4 dataset, a starting point for many LLMs, is 750 GB of text data. That’s 805,306,368,000 bytes – a lot of information. This data can include books, articles, websites, forums, comment sections, and other sources. The more varied and comprehensive the data, the better the model's understanding and generalization capabilities. While the basic transformer architecture remains the foundation, LLMs have a significantly larger number of parameters. GPT-3, for example, has 175 billion parameters. In this case, parameters refer to the weights and biases in the neural network that are learned during the training process. In deep learning, a model is trained to make predictions by adjusting these parameters to reduce the difference between its predictions and the actual outcomes. The process of adjusting these parameters is called optimization, which uses algorithms like gradient descent. 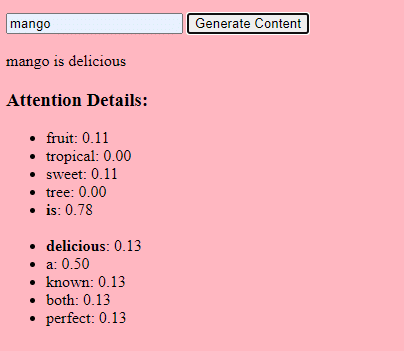
This scaling allows the model to store and process more intricate patterns and relationships in the data. The large number of parameters also means that the model requires significant computational power and memory for training and inference. This is why training such models is resource-intensive and typically uses specialized hardware like GPUs or TPUs. The model is trained to predict the next word in a sequence using powerful computational resources. It adjusts its internal parameters based on the errors it makes, continuously improving its predictions. Attention mechanisms like the ones we’ve discussed are pivotal for LLMs. They allow the model to focus on different parts of the input when generating output. By weighing the importance of different words in a context, attention mechanisms enable the model to generate coherent and contextually relevant text. Doing it at this massive scale enables the LLMs to work the way they do. How does a transformer predict text?Transformers predict text by processing input tokens through multiple layers, each equipped with attention mechanisms and feed-forward networks. After processing, the model produces a probability distribution over its vocabulary for the next word in the sequence. The word with the highest probability is typically selected as the prediction. 
How is a large language model built and trained?Building an LLM involves gathering data, cleaning it, training the model, fine-tuning the model, and vigorous, continuous testing. The model is initially trained on a vast corpus to predict the next word in a sequence. This phase allows the model to learn connections between words that pick up patterns in grammar, relationships that can represent facts about the world and connections that feel like logical reasoning. These connections also make it pick up biases present in the training data. After pre-training, the model is refined on a narrower dataset, often with human reviewers following guidelines. Fine-tuning is a crucial step in building LLMs. It involves training the pre-trained model on a more specific dataset or task. Let's take ChatGPT as an example. If you’ve played with GPT models, you know that prompting is less “write this thing” and more like
To get to ChatGPT from that point involves a lot of low-paid labor. Those people create immense corpora to put a finger on the weight of GPT responses and expected behaviors. These workers create tons of prompt/continuation texts that are like:
This fine-tuning process is essential for several reasons:
You can tell ChatGPT has been fine-tuned in particular in some ways. For example, "logical reasoning" is something LLMs tend to struggle with. ChatGPT's best logical reasoning model – GPT-4 – has been trained intensely to recognize patterns in numbers explicitly. Instead of something like this:
The training does something like this:
…and so on. This means for those more "logical" models, the training process is more rigorous and focused on ensuring that the model understands and correctly applies logical and mathematical principles. The model is exposed to various mathematical problems and their solutions, ensuring it can generalize and apply these principles to new, unseen problems. The importance of this fine-tuning process, especially for logical reasoning, cannot be overstated. Without it, the model might provide incorrect or nonsensical answers to straightforward logical or mathematical questions. Image models vs. language modelsWhile both image and language models might use similar architectures like transformers, the data they process is fundamentally different: Image modelsThese models deal with pixels and often work in a hierarchical manner, analyzing small patterns (like edges) first, then combining them to recognize larger structures (like shapes), and so on until they understand the entire image. Language modelsThese models process sequences of words or characters. They need to understand the context, grammar, and semantics to generate coherent and contextually relevant text. How prominent generative AI interfaces workDall-E + MidjourneyDall-E is a variant of the GPT-3 model adapted for image generation. It's trained on a vast dataset of text-image pairs. Midjourney is another image generation software that is based on a proprietary model.
Fingers, patterns, problems Why can't these tools consistently generate hands that look normal? These tools work by looking at pixels next to each other. You can see how this works when comparing earlier or more primitive generated images with more recent ones: earlier models look very fuzzy. In contrast, more recent models are a lot crisper. These models generate images by predicting the next pixel based on the pixels it has already generated. This process is repeated millions of times over to produce a complete image. Hands, especially fingers, are intricate and have a lot of details that need to be captured accurately. Each finger's positioning, length, and orientation can vary greatly in different images. When generating an image from a textual description, the model has to make many assumptions about the exact pose and structure of the hand, which can lead to anomalies. ChatGPTChatGPT is based on the GPT-3.5 architecture, a transformer-based model designed for natural language processing tasks.
Specialty ChatGPT's strength lies in its ability to handle various topics and simulate human-like conversations, making it ideal for chatbots and virtual assistants. Bard + Search Generative Experience (SGE)While specific details might be proprietary, Bard is based on transformer AI techniques, similar to other state-of-the-art language models. SGE is based on similar models but weaves in other ML algorithms Google uses. SGE likely generates content using a transformer-based generative model and then fuzzy extracts answers from ranking pages in search. (This may not be true. Just a guess based on how it seems to work from playing with it. Please don’t sue me!)
Applications of generative AI (and their controversies)Art and designGenerative AI can now create artwork, music, and even product designs. This has opened up new avenues for creativity and innovation. Controversy The rise of AI in art has sparked debates about job losses in creative fields. Additionally, there are concerns about:
Natural language processing (NLP)AI models are now widely used for chatbots, language translation, and other NLP tasks. Outside the dream of artificial general intelligence (AGI), this is the best use for LLMs since they are close to a “generalist” NLP model. Controversy Many users find chatbots to be impersonal and sometimes annoying. Moreover, while AI has made significant strides in language translation, it often lacks the nuance and cultural understanding that human translators bring, leading to impressive and flawed translations. Medicine and drug discoveryAI can quickly analyze vast amounts of medical data and generate potential drug compounds, speeding up the drug discovery process. Many doctors already use LLMs to write notes and patient communications Controversy Relying on LLMs for medical purposes can be problematic. Medicine requires precision, and any errors or oversights by AI can have serious consequences. Medicine also already has biases that only get more baked in using LLMs. There are also similar issues, as discussed below, with privacy, efficacy, and ethics. GamingMany AI enthusiasts are excited about using AI in gaming: they say that AI can generate realistic gaming environments, characters, and even entire game plots, enhancing the gaming experience. NPC dialogue can be enhanced through using these tools. Controversy There's a debate about the intentionality in game design. While AI can generate vast amounts of content, some argue it lacks the deliberate design and narrative cohesion that human designers bring. Watchdogs 2 had programmatic NPCs, which did little to add to the narrative cohesion of the game as a whole. Marketing and advertisingAI can analyze consumer behavior and generate personalized advertisements and promotional content, making marketing campaigns more effective. LLMs have context from other people’s writing, making them useful for generating user stories or more nuanced programmatic ideas. Instead of recommending TVs to someone who just bought a TV, LLMs can recommend accessories someone might want instead. Controversy The use of AI in marketing raises privacy concerns. There's also a debate about the ethical implications of using AI to influence consumer behavior. Dig deeper: How to scale the use of large language models in marketing Continuing issues with LLMSContextual understanding and comprehension of human speech
Pattern matching
Lack of common sense understanding
Potential to reinforce biases
Challenges in generating unique ideas
Data Privacy, Intellectual Property, and Quality Control Issues:
Bad code
Hot takes from an MLOps engineer and technical SEOThis section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me. Prompt engineering isn't real (for generative text interfaces)Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts. Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs. However, there are some critical considerations: LLMs change rapidly As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3. This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March. Uncontrollable outcomes While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don’t know what numbers are. Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself. Using LLMs in non-language-based applications is a bad ideaLLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations: Struggle with novel ideas LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word. Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs. You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it’s hard for LLMs to deal with it. 
For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life. Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.” Text-focused At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks. LLMs don't know what the truth is They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information. If they've been exposed to misinformation or biased data during training, or they don’t have context for something, they might propagate those inaccuracies in their outputs. This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount. Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it’s a name, prompts to write about it will only come up with related vectors. Designers are always better than AI-generated ArtAI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art: Intent, feeling, vibe Art is not just about the final product but the intent and emotion behind it. A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate. A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt. The post What is generative AI and how does it work? appeared first on Search Engine Land. via Search Engine Land https://ift.tt/OtKVFRG When implementing an SEO strategy, a document roadmap is crucial for several reasons:
A solid, well-researched strategy is best complemented with an SEO roadmap in Google Sheets or a tool like Jira or Asana. Ideally, leverage the technologies your teams are already using. This article discusses why an SEO roadmap is essential for your strategy. Plus, learn how to create a solid SEO roadmap to prioritize tasks and collaborate effectively with teams. What you need for an SEO roadmap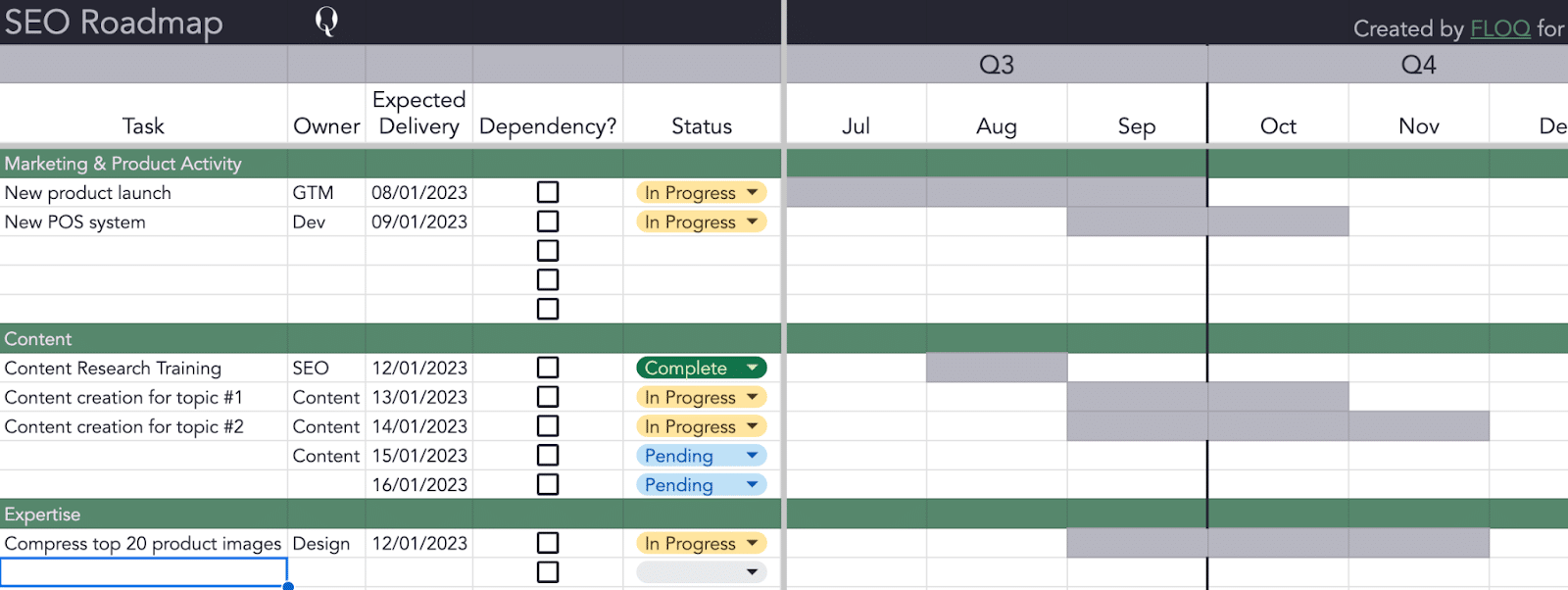
An SEO roadmap is a lot like SEO as a whole, it cannot successfully exist in a silo. That’s both in terms of your own research and your team within the wider business. Within SEO, you’d ideally have a completed SEO strategy, which includes your:
Once you have all of that, you should be able to layer it on top of your wider business context. This includes:
Gathering this information for your SEO roadmap is crucial because, initially, you’ll aim to tackle high-impact, low-effort tasks. Keep in mind that these tasks vary depending on your organization. Understanding your business goals will:
Knowing the people, tools and budget available to you may push you to reconsider where you start with your roadmap. Let’s say you’re launching a new product in the next three months, and your development team is totally at capacity until a month after that launches. Maybe you start with your content team and create new hub-and-spoke content within your organization’s area of expertise first. For example, when I worked at Optus, a major telco in Australia, folks would be hard-pressed to get any new development done on the website, large or small, from about June to September because we were preparing for the iPhone launch. (In that instance, I was a part of that launch team, so I had a bit more wiggle room to get stuff done than I would’ve otherwise, but you get the gist). You’ll also want to get a grasp on your tech stack. For some tech stack configurations, particularly on smaller websites or with SPAs, implementing a 404 server response or a 301 redirect might seem straightforward but is much more difficult and time-consuming than standard. It isn’t easy to generalize in SEO. So, while you may want to say that a high-impact, low-effort task would be to resize the 10MB images on your product pages (yes, I’ve seen this happen, and you probably have too), there may be a reason why your images are that large, or why they haven’t been compressed yet. Having all this context before putting together an SEO roadmap becomes your early indicator of those sticky situations. Steps to create your SEO roadmap1. PrioritizeThis is the first round of prioritization, the one where I estimate the SEO impact in a silo. If I look at nothing else, the one metric I look at to help prioritize is how much of the website that potential issue affects. Once I understand the scale, I look to estimate the impact. Quantifying impact can be difficult, but there are a few ways to do it:
While we can be secure in our scale and impact estimates for SEO, the one element we’re less certain of is effort. I’ll still take a stab at estimating effort, but to do it well, I bring in the experts. 2. Assign and estimateSEO can sometimes be like herding cats because you rely on other people or teams to implement your tactics. This is why I start my roadmap with what some may feel is that last step – figuring out who’ll be doing the work and speaking to them about how long they think it will take. If relevant, I’ll ask when they think they can do it and any other dependencies they’d need to do the work, like budget. I’m not an expert in design, UX, or front-end development for our website. They are. So, while I can build a rough estimate of what I think a task will take based on my own experiences with other clients or what the web generally says, it’s only a T-shirt size – one that could be off-base for reasons I don’t know. I don’t know the legacy code we have stringing through the website or the fact that it can take up to an hour sometimes to replace images on a product page because of a buggy CMS that’ll randomly not apply filename changes sometimes. I don’t know if we're amidst an unofficial code migration or running 20x CRO tests on that page. I don’t know all that stuff, but my teams do. So I take my SEO strategy, which I’ve probably worked on for months, agonized and perfected, and I pull out all the tasks I think a particular team will do. Then I take that and do a rough grooming and sizing session for those tasks with someone who knows what they’re talking about – usually, with the product owner of that squad. And if you don’t know who that is, it’s a good time to make friends. I swear, 90% of being an SEO is about being curious and kind. Note: Depending on your organization, your team might estimate differently. Sometimes, it’s in days. Other times, it’s using an agile Fibonacci scale or something similar. Whatever it is, you’ll want to be consistent. A Fibonacci scale can make translating to days in order to estimate the time frame a bit more difficult. Still, I’d lean on the team to give an average execution time so you can then put in at least an estimated delivery. This estimation process is helpful for enterprise-level companies because, assuming the conversation goes well, you’re essentially getting a soft yes from that team. That’ll make it easier for them to say yes for real when the work comes across their desk later. And then once that’s done, for me, it’s mostly paperwork. 3. Do the paperworkFor me, there’s no better format than Gantt when it comes to timed work and keeping track of it. You can build it like I typically do in Google Sheets or use software-based versions in tools like Jira or Monday. Define your headings Your headings should be your primary work areas and can be based on your strategy. For example, you may have buckets of work related to infrastructure, content or engineering. For my strategy and roadmap, I typically align my primary areas of work to the teams that will primarily be handling them because that’s how my brain keeps track of things best. Sometimes, aligning them differently, for example, with your business goals or team KPIs may make sense. This could be something like “site speed, accessibility, expertise” where site speed and accessibility would primarily be development teams, and expertise would be a mix of SEO, development and content tasks. Define your tasks Everyone has a different perspective on what tasks should and shouldn’t be included in an SEO roadmap. Two major considerations are:
I typically work with enterprise clients, so in terms of tasks, there’s not usually much I can actually do myself. What this means is my SEO roadmap is often a duplication of tasks that are assigned elsewhere, like JIRA tickets for developers or Asana tasks for designers. The SEO roadmap becomes a centralized way for me to keep track of progress on SEO initiatives all in one place rather than a to-do list for me and my team to follow. Let' say you can execute much of the work yourself, then fabulous. If tasks you can do yourself account for more than half the tasks in your roadmap, I’d suggest culling the list to focus on SEO work only and tracking non-SEO work either in a different tab in the spreadsheet or elsewhere. For the granularity of tasks, aim for the middle ground – not too big and overwhelming, but also not too small and insignificant. You wouldn’t want to include, say, “change the title tag on the blue widget page. But “change all title tags on the website” might be too large if you’re an enterprise site. A middle ground could be, “Rewrite title tag formula for product page template, ” or even “Rewrite all title tag formulas.” Something like “Product page optimization” could and should be broken into its component tasks, like:
From a practical perspective, if this is a year-long SEO roadmap, you want a manageable number of rows rather than hundreds or even thousands. You’d likely get overwhelmed and end up not feeling confident getting started. Analysis paralysis is real. 4. Re-prioritize, assign and schedule your tasksTo use the SEO roadmap well, you need to treat it with laser focus. Once you have everything bucketed and tasked and know how long they’ll take to execute, it’s time to review your priority. I prioritize tasks through a few different lenses after taking clear notes from my teams about dependencies and requirements for getting the work done. 
First, the Eisenhower matrix. This simple scale of the intersection of urgency and importance can be super grounding: more will probably end up in the “delete” bucket than you think. I generally put these in a list in my notebook or project management tool I call “If/When I Have Time.” 
This is after the initial grooming with execution teams, which probably discussed a few tasks or elements of tasks I realized weren’t worth the effort for the impact they would have. I then come back to my initial prioritization and factor in the effort estimation from my teams.
Finally, we come back to the start. With tasks re-prioritized from actual feedback from the folks that'd be doing the work, it’s time to get the ball rolling. This is when I tap execution teams on the shoulder to let them know this work should be coming their way and confirm they’ll be the ones to execute. I start those “let’s make this official” for the tasks scheduled for the next six weeks, which, if all has gone well, should be those low-effort, high-impact tasks. Drive SEO results with a well-defined roadmapIn case you weren’t sure, yes, this is a cycle. There’s a reason I started and ended my suggested process with similar tasks around assigning and estimating. A strong SEO roadmap often moves and adjusts to what's happening in the business and on the Internet. It’s an agile, living document. When creating an SEO roadmap, my advice is to:
With all that in mind, you’re armed to build a strong and flexible SEO roadmap for your clients, your business or your employer. The post How to create an SEO roadmap appeared first on Search Engine Land. via Search Engine Land https://ift.tt/Ppq6iIC Artificial intelligence (AI) is poised to become a vital tool for brands seeking to enhance their online presence. However, integrating AI into marketing strategies inevitably creates legal considerations and new regulations that agencies must carefully navigate. In this article, you’ll discover:
Legal compliance considerationsIntellectual property and copyrightA crucial legal concern when using AI in SEO and media is following intellectual property and copyright laws. AI systems often scrape and analyze vast amounts of data, including copyrighted material. There are already multiple lawsuits against OpenAI over copyright and privacy violations. The company faces lawsuits alleging unauthorized use of copyrighted books for training ChatGPT and illegally collecting personal information from internet users using their machine learning models. Privacy concerns on OpenAI’s processing and saving of user data also caused Italy to entirely block the use of ChatGPT at the end of March. The ban has now been lifted after the company made changes to increase transparency on the chatbot’s user data processing and add an option to opt out of ChatGPT’s conversations used for training algorithms. However, with the launch of GPTBot, OpenAI’s crawler, further legal considerations are likely to arise. To avoid potential legal issues and infringement claims, agencies must ensure any AI models are trained on authorized data sources and respect copyright restrictions:
Both agency and client legal teams will likely need to be involved in the above discussions before AI models can be integrated into workstreams and projects. Data privacy and protectionAI technologies rely heavily on data, which may include sensitive personal information. Collecting, storing, and processing user data must align with relevant privacy laws, such as the General Data Protection Regulation (GDPR) in the European Union. Moreover, the recently introduced EU AI Act also emphasizes addressing data privacy concerns associated with AI systems. This is not without merit. Large corporations, such as Samsung, have banned AI completely due to the exposure of confidential data uploaded to ChatGPT. Therefore, if agencies use customer data in conjunction with AI technology, they should:
In these cases, agencies can prioritize transparency in data collection by clearly communicating to users which data will be collected, how it will be used, and who will have access to it. To obtain user consent, ensure that consent is informed and freely given through clear and easy-to-understand consent forms that explain the purpose and benefits of data collection. In addition, robust security measures include:
For example, OpenAI’s policies align with the need for data privacy and protection and focus on promoting transparency, user consent and data security in AI applications. Fairness and biasAI algorithms used in SEO and media have the potential to inadvertently perpetuate biases or discriminate against certain individuals or groups. Agencies must be proactive in identifying and mitigating algorithmic bias. This is especially important under the new EU AI Act, which prohibits AI systems from unfairly affecting human behavior or displaying discriminatory behavior. To mitigate this risk, agencies should ensure that diverse data and perspectives are included in the design of AI models and continuously monitor results for potential bias and discrimination. A way to achieve this is by using tools that help reduce bias, like AI Fairness 360, IBM Watson Studio and Google’s What-If Tool. False or misleading contentAI tools, including ChatGPT, can generate synthetic content that may be inaccurate, misleading or fake. For example, artificial intelligence often creates fake online reviews to promote certain places or products. This can lead to negative consequences for businesses that rely on AI-generated content. Implementing clear policies and procedures for reviewing AI-generated content before publication is crucial to prevent this risk. 
Another practice to consider is labeling AI-generated content. Although Google seems not to enforce it, many policymakers support AI labeling. Liability and accountabilityAs AI systems become more complex, questions of liability arise. Agencies utilizing AI must be prepared to take responsibility for any unintended consequences resulting from its use, including:
The EU AI Act introduces new provisions on high-risk AI systems that can significantly affect users’ rights, highlighting why agencies and clients must comply with the relevant terms and policies when using AI technologies. Some of OpenAI’s most important terms and policies relate to the content provided by the user, the accuracy of responses and the processing of personal data. The content policy states that OpenAI assigns the rights of the generated content to the user. It also specifies that generated content can be used for any purpose, including commercial, providing it complies with legal restrictions. However, it also states that output may be neither completely unique nor accurate, meaning that AI-generated content should always be thoroughly reviewed before use. On a personal data note, OpenAI collects all information users input, including file uploads. When using the service to process personal data, users must provide legally adequate privacy notices and fill out a form to request data processing. Agencies must proactively address accountability issues, monitor AI outputs, and implement robust quality control measures to mitigate potential legal liabilities. AI implementation challenges for agenciesSince OpenAI released ChatGPT last year, there have been many talks on how generative AI will change SEO as a profession and its overall impact on the media industry. Although changes come with a mix of enhancements to the daily workload, there are some challenges agencies should consider when implementing AI into client’s strategies. Education and awarenessMany clients may lack a comprehensive understanding of AI and its implications. Agencies, therefore, face the challenge of educating clients about the potential benefits and risks associated with AI implementation. The evolving regulatory landscape necessitates clear communication with clients regarding the measures taken to ensure legal compliance. In order to achieve this, agencies must:
A way to do that is by having a fact sheet to share with clients containing all the necessary information and, if possible, provide case studies or other examples of how they can benefit from using artificial intelligence. Resource allocationIntegrating AI into SEO and media strategies requires significant resources, including financial investments, skilled personnel and infrastructure upgrades. Agencies must carefully assess their clients' needs and capabilities to determine the feasibility of implementing AI solutions within their budgetary constraints, as they may require AI specialists, data analysts, SEO and content specialists that can effectively collaborate together. Infrastructure needs may include AI tools, data processing and analytics platforms to extract insights. Whether to provide services or facilitate external resources depends on each agency's existing capabilities and budget. Outsourcing other agencies might lead to quicker implementation while investing in in-house AI capabilities might be better for long-term control and customization of the offered services. Technical expertiseAI implementation demands specialized technical knowledge and expertise. Agencies may need to recruit or upskill their teams to effectively develop, deploy, and manage AI systems in line with the new regulatory requirements. To make the most of AI, team members should have:
Ethical considerationsAgencies must consider the ethical implications of AI use for their clients. Ethical frameworks and guidelines should be established to ensure responsible AI practices throughout the process, addressing the concerns raised in the updated regulations. These include:
Accountability matters: Meeting the legal challenges of AI implementationWhile AI presents exciting opportunities for improving SEO and media practices, agencies must navigate legal challenges and adhere to the updated regulations associated with its implementation. Businesses and agencies can minimize legal risks by:
The post AI in SEO: How to navigate legal challenges and ensure compliance appeared first on Search Engine Land. via Search Engine Land https://ift.tt/3asN9L8 |
Archives
April 2024
Categories
|

