INTERNET MARKETING SUCCESS

|
Google announced today a new Page Experience Update and along with this Google will no longer require AMP for the mobile version of the Top Stories section in Google search. This won’t happen until sometime in 2021, but it is important to note that page experience will be a vital factor when determining what content shows in the Top Stories section. What goes in top stories now? Back in 2016, Google said that only AMP pages could show up in the Google mobile version of top stories in Search. Just recently, Google let some local news providers for COVID-19 related stories bypass this requirement. When this Page Experience goes live in 2021, Google will no longer require AMP for the top stories news section. You just need to make sure your pages do well in terms of the Page Experience scores. AMP still can show in top stories. AMP can and will still be displayed in the Google Top Stories section after this update. In fact, Google’s Rudy Galfi told us that the majority of AMP pages already perform very well across all the page experience factors. But if you do not have AMP, then those non-AMP pages can now also rank well in Top Stories. Google wrote “when we roll out the page experience ranking update, we will also update the eligibility criteria for the Top Stories experience. AMP will no longer be necessary for stories to be featured in Top Stories on mobile; it will be open to any page.” Google added, “alongside this change, page experience will become a ranking factor in Top Stories, in addition to the many factors assessed. As before, pages must meet the Google News content policies to be eligible. Site owners who currently publish pages as AMP, or with an AMP version, will see no change in behavior – the AMP version will be what’s linked from Top Stories.” Why we care. This change will open up more publishers to be able to show up in the Top Stories section on mobile. That means more competition for your traffic and your keywords. But it also means that you can optimize your non-AMP pages to do well in the mobile Top Stories section and outrank your competitors that may have decided to use AMP. It also means that if you dislike using AMP and maintaining AMP pages, you can do away with them and have your normal mobile pages rank in the Top Stories section. Reminder; this is not live today, it won’t be live until sometime in 2021 when Google launches the new Page Experience Update. The post AMP won’t be required for Google’s Top Stories section appeared first on Search Engine Land. via Search Engine Land https://ift.tt/36JS79V
0 Comments
Google today announced a new ranking algorithm designed to judge web pages based on how users perceive the experience of interacting with a web page. That means if Google thinks your website users will have a poor experience on your pages, Google may not rank those pages as highly as they are now. This update is called the Google Page Experience update and is not expected to go live until sometime in 2021, so you have plenty of time to prepare. What is page experience? Google has a detailed developer document on the page experience criteria but in short, these metrics aim to understand how a user will perceive the experience of a specific web page: considerations such as whether the page loads quickly, if it’s mobile-friendly, runs on HTTPS, the presence of intrusive ads and if content jumps around as the page loads. Page experience is made up of several existing Google search ranking factors, including the mobile-friendly update, Page Speed Update, the HTTPS ranking boost, the intrusive interstitials penalty, safe browsing penalty, while refining metrics around speed and usability. These refinements are under what Google calls Core Web Vitals. What are core web vitals. Core Web Vitals include real-world, user-centered metrics, that give scores on aspects of your pages including load time, interactivity, and the stability of content as it loads. These metrics fall under these metrics:
What it all looks like. When you group these all together, you get this page experience name for all these elements. Google said page experience specifically is not a ranking score, but rather, each element within has its own weights and rankings in the overall Google ranking algorithm. 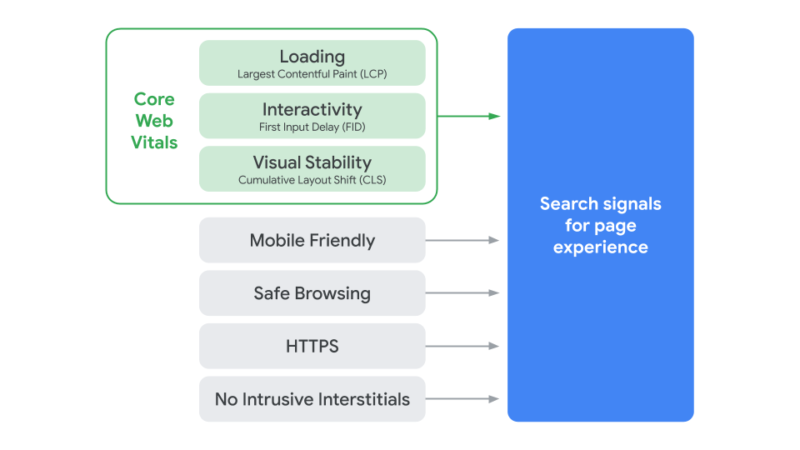
What are all these factors. We linked to most of them above, but here is how Google documents each individual factor within page experience:
Cumulative Layout Shift (CLS). This is a new metric that basically looks at if the page is stable when it loads (i.e., do images, content, buttons move around the page as the page loads or does the page stay put and solid). In short, is the layout of the page shifting, resulting in a poor user experience. Google shared a GIF of this in action: 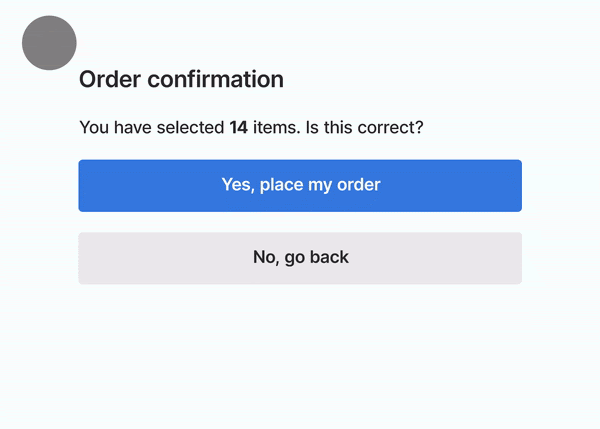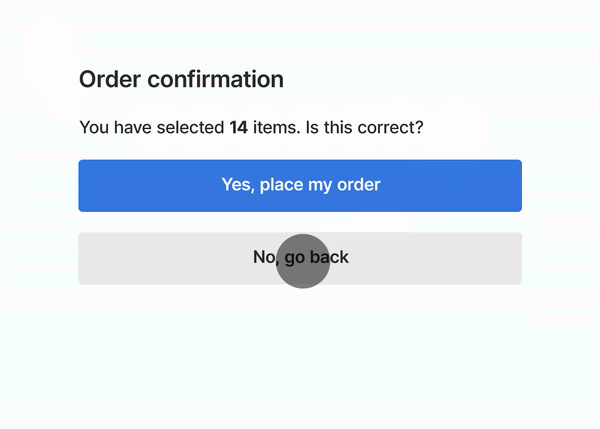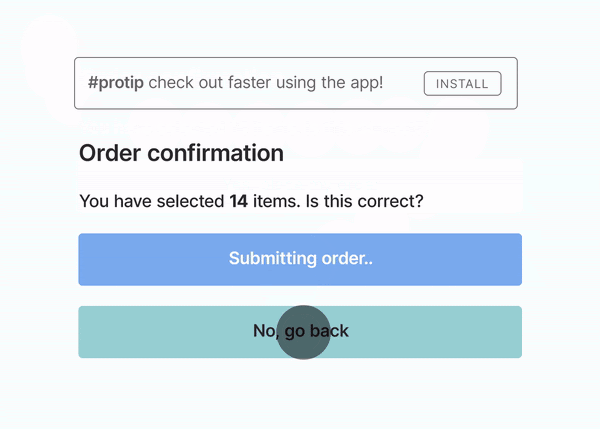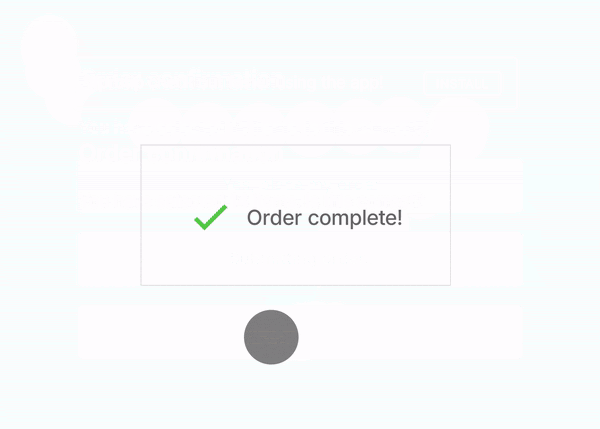
Prepare for this update. Google said this is not going live today, there are no new ranking factors going live today. This will go live sometime in 2021, Google promised to give six-months notice before it goes live. Google is giving us time, not just because Google normally gives us a heads up to prepare for these updates, but also because of the unstable environment we are all living through during this pandemic. We will update you all when Google announces a date for the release of this update. You can prepare now for all of these ranking changes with the tools listed above. You can also use the new Core Web Vitals report in Google Search Console that was released yesterday. How big of an update will this be? We have heard from Google about previous Google updates, how some like Panda’s initial released impacted 11.8% of all queries, or Google BERT impacted 10% of queries, or that HTTPS is a small factor. But with this update, we don’t know yet. We spoke with Rudy Galfi, the product lead on the Google Search ecosystem team, and he said they are not discussing how much each factor is weighted. Rudy did say that great content will still be the more important factor and great content with a poor page experience can still rank highly in Google search. Great content is still supreme. Google made it clear that great content will still rank highly in Google Search, despite a poor page experience. “While all of the components of page experience are important, we will rank pages with the best information overall, even if some aspects of page experience are subpar. A good page experience doesn’t override having great, relevant content. However, in cases where there are multiple pages that have similar content, page experience becomes much more important for visibility in Search,” Google wrote. Top Stories. As we covered in our AMP won’t be required for Google’s Top Stories section, AMP is no longer required for inclusion in the Top Stories section in the mobile Google search results. What will matter is that Google will look at the page experience scores and this will play a vital role in what content shows in Google’s Top Stories section, Rudy Galfi told us. AMP. AMP will still surface in the Google mobile search results if you have AMP pages. That is not changing, but what is changing is that now your AMP pages will compete with other pages for the Top Stories section in Google. If you have AMP, the good news is that the majority of AMP pages do extremely well in terms of page experience metrics, Rudy Galfi said. It doesn’t mean that all AMP pages will have top page experience metrics, but AMP is built in a way to help with this. Google on mobile will use the page experience metrics from your AMP content. Since Google serves AMP pages on mobile, if you have an AMP version of your page, then Google will use the AMP page experience metrics for scoring purposes. Again, it is what Google serves to the user that will be judged for ranking. Why we care. Google has announced a set of new ranking factors under the page experience name. This means that we have until 2021 to prepare for this ranking update. Use the tools Google has given us to get our sites and our client sites ready for this update. We will keep you posted on when this new update is going live and what else you can do to prepare for this change. Check out SMX Next. Don’t forget to register for our free SMX Next virtual conference. One of the keynotes will be about the timeline of Google algorithm updates and where you need to be in order to be prepare for this and future algorithm updates. The post The Google Page Experience Update: User experience to become a Google ranking factor appeared first on Search Engine Land. via Search Engine Land https://ift.tt/3cbQP8A 
Since its introduction in 2012 the Google Disavow Tool has become an indispensable instrument for website operators and online marketers It is the only method of positively mitigating backlink risks and maintaining off-page signals. If used correctly, the Disavow Tool becomes a one-way communication channel with Google. The wider application of the Disavow Tool and the vast amounts of data that it continues to generate for Google remains a source of speculation. It’s main purpose, at least from the website operator’s point of view, remains the dissociation of their website from PageRank passing backlinks that may otherwise hold organic search visibility down. When used carelessly, however, the Disavow Tool can spell doom for Google Rankings. This Ultimate Google Disavow Guide, strongly influenced by the author’s professional experience while working for Google Search, both penalizing offending websites as well as lifting Google penalties, is an attempt to clarify frequent misbeliefs around the Google Disavow Tool and its application. At the same time, it is an effort to address commonly associated questions and provide a blueprint for anyone considering using the Disavow Tool in order to improve their website signals.
Disavow or not to disavow?Ostensibly there is a central question: does every website require a disavow file? The unequivocal answer to that question is a resounding: no! Not every website needs a compelling disavow file. In fact, in the scale of things, relatively few websites need to actively monitor and manage their backlink signals. Websites such as personal blogs, government platforms, charities, non-governmental websites, even small niche or local webshops frequently aren’t in acute need to disavow spam backlinks. The reason for this is that these websites rarely conduct link building. Many thrive on direct traffic and have neither the capacity nor the desire to improve their Google rankings. Often their target audience is aware of and familiar with their presence. Hence type-in traffic represents almost all of the traffic they enjoy. Consequently, they rarely if ever actively pursue PageRank, passing backlinks that Google, in turn, may frown upon. With relatively few backlinks in all, disavowing is virtually a non-issue. It is an entirely different situation when looking at commercial websites, such as online shops, price comparison platforms, market places, media outlets, portals or major brands. Their overriding commercial intent makes them susceptible to optimization, which may or may not always have been Google Webmaster Guidelines compliant. Google remains adamant with regard to, in Google’s mind, not merit based backlinks, hence managing backlink risks is for these websites a critical part of conducting online business. They need to use the Disavow Tool as a shield protecting their organic rankings. There’s also a situation where every affected website must use the Disavow Tool in their defense. That’s when a Google manual spam action aka manual penalty due to link building is in place. As a general rule, any Google penalty should be removed as swiftly as possible. However, a penalty in relation to backlinks, in particular, must be addressed immediately, since it progressively impacts the website’s position in Google Search Results. 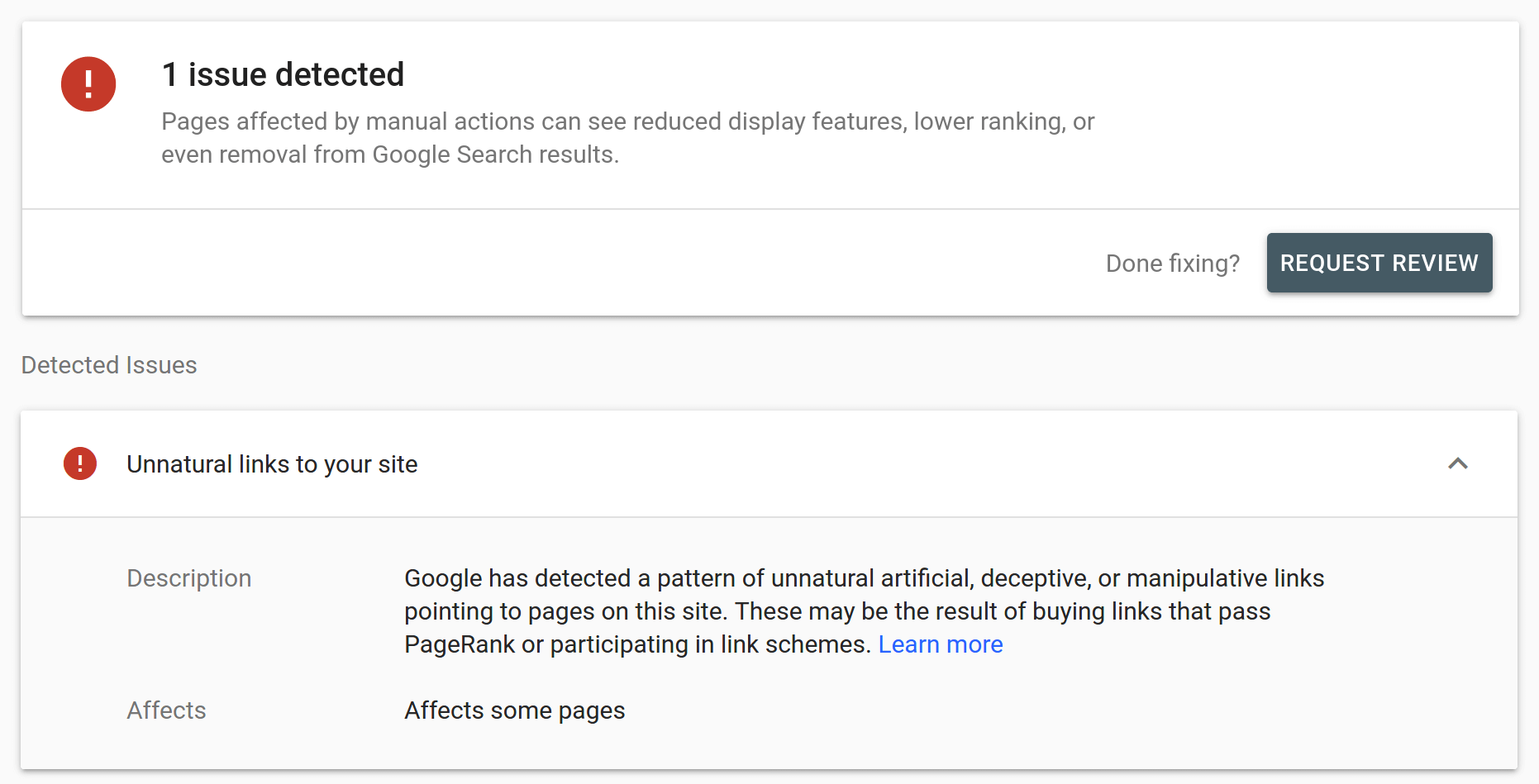
When to disavow?There are a number of important, yet only two main factors which must be considered if backlinks may constitute a liability for the website: the volume of incoming backlinks and their quality. The first indicator can frequently be gauged almost instantly, by looking at the total number of backlinks reported in trustworthy third party tools such as Majestic. For example, the minimum number of backlinks ever recorded pointing to example.com is the sum of fresh and historic total combined. While no single tool is capable of providing an exact figure, approximately 300 million backlinks is a substantial number that in case of a commercial website may warrant a review and updating the disavow file. Majestic, similarly to other great data gathering tools recommended later in this guide, is unlikely to detect all backlinks ever to be in existence. Like all other commercial tools, it may not identify private (blog) backlink networks, created specifically in order to avoid third party detection. PBNs are however a ludicrous concept from its inception. Link building is explicitly done for Google, backlinks must be detectable by Google and therefore always pose a clear liability to the website’s rankings. Google Search Console, while indispensable in the process, can’t be considered as the ultimate data source because of the build in reporting limit, capping samples at 100.000 backlinks. That having said, when looking for a tangible threshold 100.000 backlinks may be taken as a rule of thumb. Fewer backlinks likely do not warrant the effort required for disavowing. More backlinks may, potentially. The second main indicator -quality- is significantly less simple to even ascertain, let alone to accurately assess. Backlink quality depends on the type of anchor text used, anchor text distribution, the quality of content surrounding backlink anchors, as well as where else the same page links to. In a nutshell, it can only be analyzed by experienced human experts armed with powerful, purpose built tools which help to expedite the process. No tools however can fully replace this labour intensive, detail oriented approach. Manual analysis and investigating backlink quality requires crawling backlink data in a first, critical step. Short of going through the entire process, there’s one additional indicator which can help to gauge how much of an acute risk a backlink profile may pose: the anchor text distribution. While there are no hard thresholds to observe, the ground rule is that the more the top ten anchor texts appear optimized for the specific products or services offered, the higher the probability that PageRank passing link building was conducted at some point in time. And that consequently legacy and fresh backlinks are more likely to pose a serious risk. Several tools offer insights in this regard, including Ahrefs and Majestic, with varying depth. Evaluating all but the top 10 anchor texts is however superfluous, since commercial anchors tend to surface to the top anyway. 
What to disavow?Any backlink analysis must begin with aggregating as much relevant backlink data as possible. Google Search Console backlink samples are a stepping stone towards that purpose. As mentioned previously, these are limited, effectively reducing their informative value for websites with substantial backlink profiles of 10 million backlinks and more. While it is possible to boost the GSC sample output by adding a multitude of patterns next to domain property, such as with www. and without www., both https and http as well as a combination of all the above and possibly other subdomains or directories, these steps remain a work-around. Google’s continuous insistence on the matter that GSC samples are sufficient for any eventuality is true, yet only for relatively small websites. Websites which over time accumulated substantial backlink profiles must not rely on GSC samples alone. A cost-effective, yet time-consuming option can be collecting backlink data samples from other search engines webmaster tools as well. Similarly to Google Search Console, the Bing Webmaster Tool BETA feature offers a free of charge glimpse at the backlink data. On a side note, Bing also allows webmasters concerned with Bing rankings to disassociate their websites from undesirable backlinks, not unlike Google does. This Ultimate Google Disavow Guide however is solely focussed on Google best practices. Other leading search engines webmaster tools, such as Yandex or Baidu can be useful to collect yet more backlink data over a period of time. While the former however seems to take a long time before amassing and displaying backlink data, the latter poses a formidable language challenge for many website operators. As mentioned, none of the search engines provided data samples, mentioned alone or even combined, is complete enough when reliable data is acutely needed. In a critical situation it is of the greatest importance that other third party data samples are also taken into consideration in order to generate a sufficient data sample for actionable results. Here again ideally a multitude of different tools such as Ahrefs, Majestic, SEMrush, Ryte and LinkResearchTools should be used in order to accumulate and verify as much backlink data as possible. However, this redundant approach comes at a cost. The few high-quality services available come at a price, which can become substantial, once individual backlink data exports exceed 100 million backlinks. That modest number also dispels any lingering doubts whether Google Search Console backlink samples possibly could be sufficient for a through backlink analysis. Google Search Console capped 100 thousand backlink examples represent 0.1% sample of a 100 million backlink profile. A number hardly sufficient to cleanse a website of problematic link building past. When the potentially time consuming process of collecting data is finalized, the samples collected are deduped and filtered in order to expedite the following, necessarily manual review process. Zero impact backlinks e.g. pointing to landing pages which are excluded in the websites robots.txt file or backlinks bearing a rel=”nofollow” attribute can be immediately dropped from consideration. They are inconsequential from a spam risk assessment perspective. Both the attributes rel=”sponsored” and rel=”ugc”, which at this point remain scarcely applied novelties do not require any differentiated approach. They are exclusive to Google and not recognized by any other search engine, which is why if they were to be used at all, they must be applied in tandem with the industry-wide standard . Similarly to backlinks that have no impact, there are also websites which can legitimately cross link, even using the most commercial anchor texts imagined, because they share ownership. In other words a website operator or organisation is at liberty to cross link their websites without risking violating Google Webmaster Guidelines. Hence the entire website/domain portfolio should be excluded from further analysis. Contrary to that situation, subjectively high authority or respectable brand websites should not be whitelabeled in a similar fashion. There are a lot of misconceptions around authority, most of all highlighting an elusive DA or domain authority value. The term so often tossed around is in-fact not relevant to Google. Experience shows that presumably respectable websites or brands frequently are in violation with Google linking policies. A fact not lost on the Google team. Therefore backlinks originating from what may be considered respectable sources must not be evaluated in any other way. Equally high risk backlinks that are about to be removed entirely, changed or nofollowed, still need to be included in the evaluation process. If deemed a threat, they all must be included in the disavow file, despite the fact they may have changed already. Google may not have crawled them anew yet. Consequently changed signals may not be reflected in Google data and algorithms either, which makes such backlinks a lingering threat. If and when such backlinks are recrawled depends on the websites individual crawl budget allocation and management. And it can take some time, especially in case of low quality sites. When commencing the analysis the backlinks intent, why they came to existence, and not ownership or origins remains in the focus of the investigation. Google neither asks nor cares how exactly spam backlinks came into existence, who created them or when. Therefore it isn’t necessary to record additional information for later processing or documentation purposes. With fresh backlink data at hand, high probability spam backlinks can be grouped together. While every website’s backlink profile is different and constantly changing, there are backlinks that can with 100% certainty be regarded as a liability and securely disavowed. Templated spam, including auto generated websites with none, scraped or gibberish content are firmly within this group and must be disavowed. High Risk TLDsNo TLD can be considered 100% spam. None should be disavowed merely on the grounds of the linking sites TLDs. There are however some TLDs which tend to over proportionally attract spam. The Spamhaus Project 2020 Top 10 statistics are rather revealing in this regard, even if the list isn’t comprehensively long. Backlinks originating from websites hosted on domains such as .tk, .gq, .top, .ml or .loan to name just a few among many TLDs that can not be outright dismissed as spam, but in the backlink review process they can be filtered and grouped together. Often repetitive patterns in their domain naming or URL structure, identical templates and gibberish, easy to spot content help to make a swift risk assessment. The situation is similar, yet slightly more nuanced, with spam free-hosting services. Every free-host does of course include some low quality websites. Some however notoriously fail to rid themselves of auto-generated spam, which in the past triggered a collective punishment reaction on Google’s part. These arguably few publicly noticed instances demonstrate that Google did and does care about free-hosts. There is no need to preemptively include free-host services into the disavow file, however when dodgy free-hosted websites are identified in the course of the backlink analysis, there is no need to proceed with caution. Free-hosted spam backlinks justify including all of the service using the domain: operator to the disavow file. 
Expired domains backlinksWhile investigating backlink risk levels, some sites or, in this instance, domains are more easily recognized as spam and therefore harmful then others. Expired domains, that’s previously legitimate websites, dropped by their original operators just to be revived with scraped or templated content in the hope to benefit from reputation built in the past. They are a clear violation of Google Webmaster Guidelines and a black hat SEO smoking gun. Consequently all expired domains must be disavowed. Such sites are almost universally auto generated and therefore easily to spot and to filter. Where there is even a shadow of a doubt, the Internet Archive provides invaluable and free of charge services, showing most sites past records. 

Hacked sites backlinksSimilarly to expired domains, all legitimate yet compromised e.g. hacked websites, unknowingly linking through injected code without the legitimate operators consent, must be disavowed. Since this method as a trend is in decline, typically even for very large backlink profiles there will be only a hand-full of hacked websites in their backlink profile. This is the only group which may be revisited periodically to reassess the situation. Sites that have been cleansed of injected backlinks and content can be safely removed for the disavow file, however this is an optional step. Press release backlinksPageRank passing press release backlinks, especially the ones bearing commercial anchor texts as mentioned specifically in Google Linking Guidelines, must all be included in a compelling disavow file. Google has time and again highlighted their stands on press release link building and maintains their position that doing so is a clear Webmaster Guidelines offence. Veteran Google employees including John Muller have repeatedly reiterated on the specific point. Affiliate backlinksGoogle does not look unkindly at affiliate websites in general. PageRank passing affiliate backlinks however, are considered a thorn in the side, since they are not merit based as far as Google is concerned. Consequently, when managing backlink risks, all affiliate backlinks must be included in the disavow file. Coupon or special deals websites, as well as price comparison platforms, are worthy of special attention. By far not all of these legitimate services choose to ignore Google Linking Guidelines intentionally, however the ultimate responsibility to check, remains as with all backlinks with the site operator concerned for his or her websites Google rankings. Directories backlinksAll SEO and link directories must be disavowed. At this point there are no legitimate reasons to make any exceptions. There are countless giveaways betraying the sole purpose for directories existence, which is passing PageRank. Among these are the fact that almost no directories are moderated, they lack topicality or any oversight and frequently even the domains used highlight SEO or links rather than any other editorial value. While frequently and rightly seen as a legacy issue, directory backlinks remain a liability for websites even many years later. 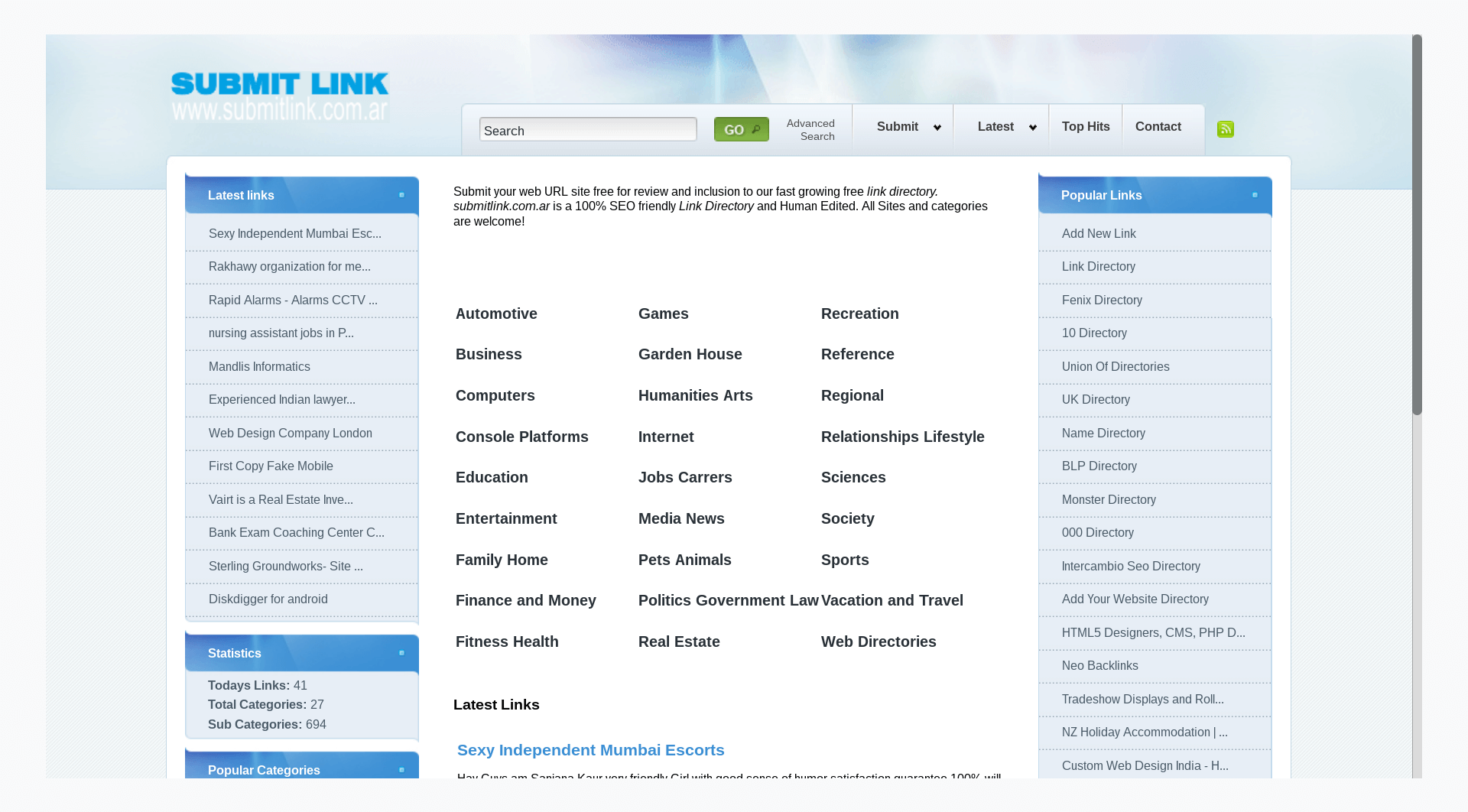
Off-topic forums backlinksAs previously mentioned, PageRank passing spam backlinks have no expiration date. As long as they exist, they continue to pose a threat. Which is why even truly antiquated black hat link building methods like SEO directories and off-topic forum spamming must be included in the analysis. Especially the latter bares some serious legacy potential to cause harm, with efficient software solutions like XRumer on the market for a decade. Of course, not all forum backlinks are harmful to the target website. On the contrary, relevant, community-driven and moderated forum references can be great. And most importantly, drive converting traffic too. However, these are in a manual review easily separated from the spam entries, from junior form members that have little substance and no standing in the respective community. The latter type of spam backlinks must be disavowed. Paid blogs backlinksWhile the above mentioned types of link spam are usually swiftly identified based on similarities, it is paid blog posts that require more scrutiny. The decisive factor for determining the risk that paid blog posts cumulatively pose is intent. In other words, if the quality of the website linking, the depth of its contents, its unrestrictive linking policies, as well as the type of anchor text used and the landing page the backlinks point to indicate intent to benefit from passing PageRank, such backlinks pose a risk. They must be disavowed. While paid blogging is rarely done with quality in mind, short of relying on tested CMS’ and reliable, cheap hosting such as WordPress paid blogs do not necessarily display the same level of uniformity that allows for efficient filtering in the review process. Like all of the types of spam specifically mentioned in this guide, paid blog backlinks require a manual review in preparation for a risk assessment and in order to build a compelling disavow file. When in-doubt these are some questions that may help ascertain, whether a backlink is a risk contributing factor and possibly should be disavowed:
If it isn’t, either because of a rel=”nofollow” attribute or because the landing page is robots.txt-ed out, it does not pose a problem. All subsequent questions become obsolete. If the backlink is passing PageRank, addressing the following questions can help:
If any of these questions are met with a positive response, the backlink likely is a risk factor. Ultimately, the key question that can help to determine if a backlink is legitimate as far as Google is concerned or not as much is: Would you be comfortable sharing this link with a competitor or a Google Search employee? That latter question answered rarely fails to sort the wheat from the chaff. How to disavow?Once the analysis is complete a few, albeit important steps remain. Google does provide some guidance regarding the formatting and disavow file limitations set. The two most obvious limits, which are maximum 2MB file size and a total of 100.000 URLs constrain few, but the most heavily link spammed websites on the web. Avoiding individual, granular patterns and always utilizing the domain: operator on site level [e.g. domain:example.com] are basic best practices to abide. The correct file format of the .txt document which must be UTF-8 or 7-bit ASCII remains the last important point to consider. As long as it ends on .txt the file name used is inconsequential. Website operators can verify the validity of their disavow file using the only free of charge Disavow File Testing Tool website, created by ex-Google engineer and fellow Search Engine Land author Fili Wiese. No tool, however, can detect contextual errors, such as disavowing one’s own domains, which can and should legitimately cross-link. This is why a final check should ensure no relevant, legitimately linking domains that belong to the same website operator are included. 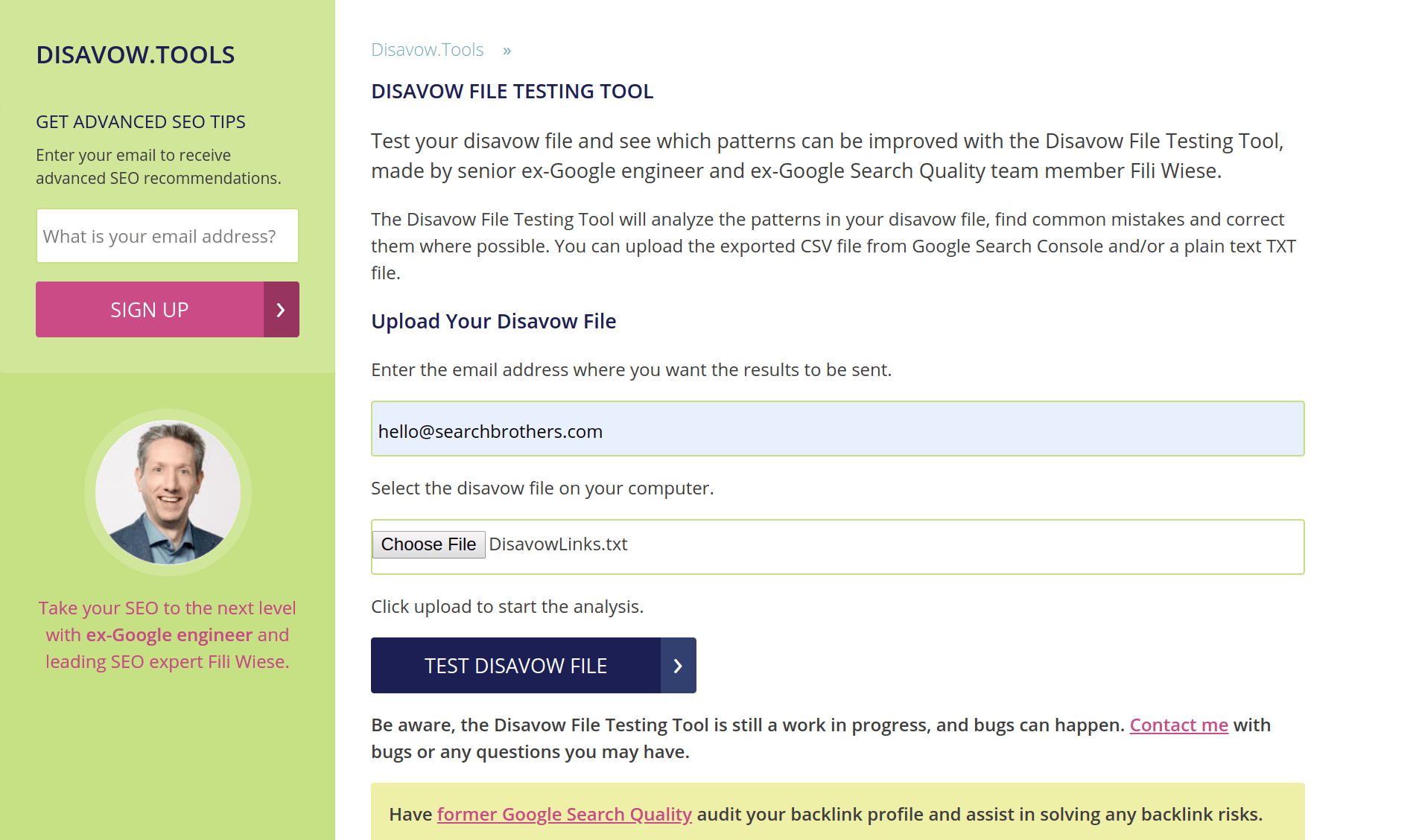
Another hack in the final step is to submit the disavow file individually to all verified Google Search Console patterns, including all combinations, such as with www. and without www., https and http as well as any other subdomains and directories. While Google officially recommends to focus exclusively on the primary property, this seemingly redundant effort, can help to protect the website from undesirable backlinks in a rare case of Google systems failing, whether temporarily or critically. A finalized and double-checked disavow file is best submitted without delay. Backlink profiles of all websites evolve and change constantly. New backlinks come into existence, desirable ones as well as spam backlinks. That’s why disavow files degenerate over time. That process happens faster for websites with already relatively large backlink profiles. Which is why a finalized disavow file represents a temporary remedy. The value of which declines as time passes. 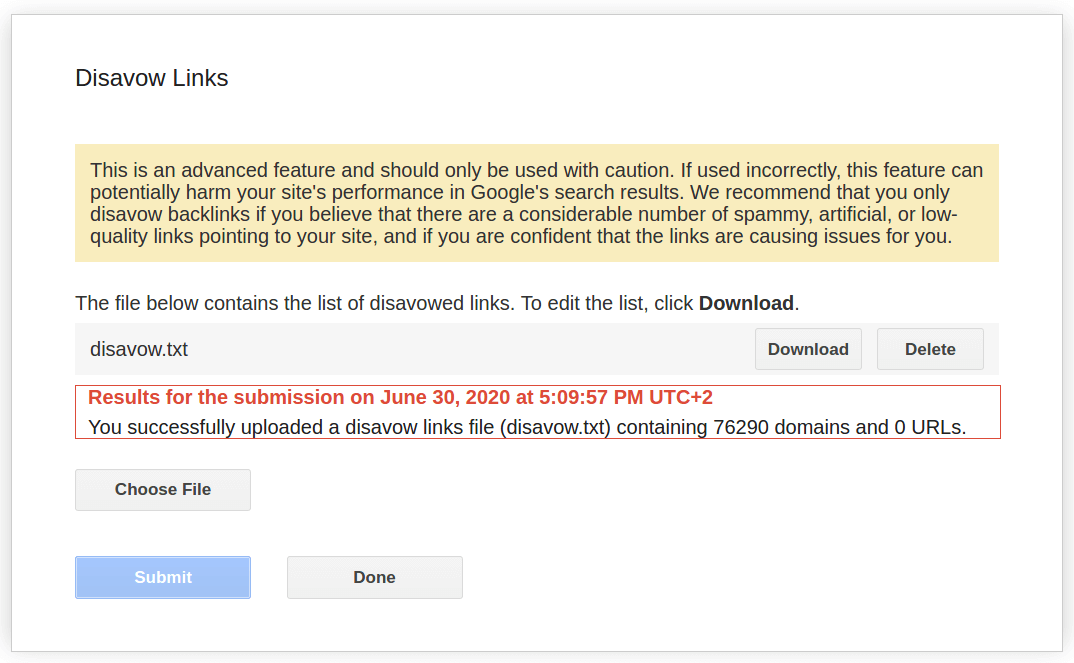
What’s next?For Google an individual disavow file represents a website operator recommendation, not a directive. Whether it chooses to follow that recommandation in full or partially isn’t however disclosed via Google Search Console. For the website operator, the very same disavow file represents a temporary protection shield. For how long it may provide some level of confidence, depends on subsequent backlink growth and its quality. While there are few general rules to follow, a disavow file should be revisited and updated based on fresh data at least once per year, as part of an annual maintenance cycle. When that reiteration happens, previously disavowed and newly detected spam backlink patterns must be combined into one new disavow file before uploading. Merely uploading new patterns will inevitably and irreversibly delete previously submitted spam backlink patterns and thereby undo the past good work. The submitted disavow file has at the same time no impact on converting traffic forthcoming from included backlinks. In other words, while backlink risks are mitigated, whatever traffic may originate from the same suspicious backlinks, isn’t affected. 
There are no methods of confidently predicting traffic trajectory after disavowing spam backlinks in Google. Three scenarios are distinctly possible. Websites traffic can stagnate, sharply increase as back link ballast is removed or drop significantly. Disavowing questionable backlinks isn’t about growing traffic though. That’s what an on- and off-page technical audit is for. Disavowing helps to maintain the website’s off-page signal input. At the same time, the very fact that Google penalizes websites for building PageRank passing links demonstrates without any doubt that link building, including risk-taking link building in violation with Google Webmaster Guidelines, can work. Above and beyond, passing PageRank links as a ranking factor is here to stay and must be considered as an important SEO signal, especially for content discovery, searchbot crawl prioritization, user navigation and converting traffic. There are risk-averse, conversion-oriented alternative approaches towards building backlinks, as comprehensively covered in the How to build links article, which offers a new perspective. One that, if fully embraced, can also help to reduce the need to disavow backlinks in the future to come. The post The Ultimate Google Disavow Guide appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2TMHxKd “I don’t know why people are reinventing the wheel,” said Martin Splitt, search developer advocate for Google, during our crawling and indexing session of Live with Search Engine Land. As more and more techniques are developed to provide SEOs and webmasters with flexible solutions to existing problems, Splitt worries that relying on these workarounds, instead of sticking to the basics, can end up hurting a site’s organic visibility. “We have a working mechanism to do links . . . so, why are we trying to recreate something worse than what we already have built-in?” Splitt said, expressing frustration over how some developers and SEOs are diverging from the standard HTML link in favor of fancier solutions, such as using buttons as links and forsaking the href attribute for onclick handlers. These techniques may create problems for web crawlers, which increases the likelihood that those crawlers skip your links. Another common issue arises when SEOs and developers block search engines from accessing certain content using the robots.txt file, still expecting their JavaScript API to direct the web crawler. “When you block us from loading that, we don’t see any of your content, so your website, as far as we know, is blank,” Splitt said, adding “And, I wouldn’t know why, as a search engine, would I keep a blank website in my index.” Why we care. “Oftentimes, people are facing a relatively simple problem and then over-engineer a solution that seems to work, but then actually fails in certain cases and these cases usually involve crawlers,” Splitt said. When simple, widely accepted techniques already exist, site owners should opt for those solutions to ensure that their pages can get crawled and subsequently indexed and ranked. The more complex a workaround is, the higher the chances are that the technique will lead to unforeseen problems down the road. Want more Live with Search Engine Land? Get it here:
The post Common oversights that can impede Google from crawling your content [Video] appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2zuyCpS Shopify’s platform makes it simple for beginner store owners to launch their e-commerce sites, but that convenience means that many of the technical aspects of your site have been decided for you. This introduces some Shopify-specific quirks that you may run into when optimizing your site architecture, URL structure, and use of JavaScript. The basic search optimizations that all Shopify store owners should be aware of are already covered in our main Shopify SEO guide. In this guide, we’ll help you finetune your Shopify site’s technical SEO to help search engines crawl and index your pages. Tackle duplicate pagesShopify implements collections for grouping products into categories, making it easier for customers to find them. One drawback to this is that products belonging to collection pages create a duplicate URL issue. Technically speaking, Shopify collections is an array for storing Products semantically attached by convention (instead of by ID) to resource routing. /config/routes.rb
This maps the URL to a corresponding product controller action “collections” and resources. When you associate a product with a collection page (as just about every merchant selling more than a handful of items is likely to do), Shopify automatically generates a second URL to that product page as part of the collection. This means you’ll have two URLs pointing to the same product; the URLs will appear as follows:
Duplicate content makes it more difficult for search engines to determine which URL to index and rank, and having multiple URLs for the same page can split your link building power because referrers may use either URL. With the use of the canonical tag you have an adequate solution for the first problem, but not the second. The canonical tag was introduced by search engines to designate which spelling of URLs (that load the same content) is the preferred spelling for search results. There are many ways multiple spellings can come about, and Shopify’s use of collections generates duplicate URLs for products that belong to collections. Shopify points collection page canonical tags to the product page, which is excellent, but doesn’t solve the split links problem. Eliminating alternate URLs. Fortunately, there is a known solution that you can use to resolve the issue within your templates, and you wouldn’t necessarily have to be familiar with the syntax (known as Liquid) that the template is built with. Although your mileage will vary depending on the theme you’re using, the edit you would employ should be fairly straightforward and involve an output filter “within: collection.” To get started with this solution, you’ll first need to log into your Shopify account. From there, access your store’s theme by clicking on Online Store and then Themes from the left-hand sidebar. Next, click Customize in the Current theme section of the interface, as shown below. 
In the next screen, click on Theme actions (located at the bottom of the left-hand sidebar) and then Edit code. 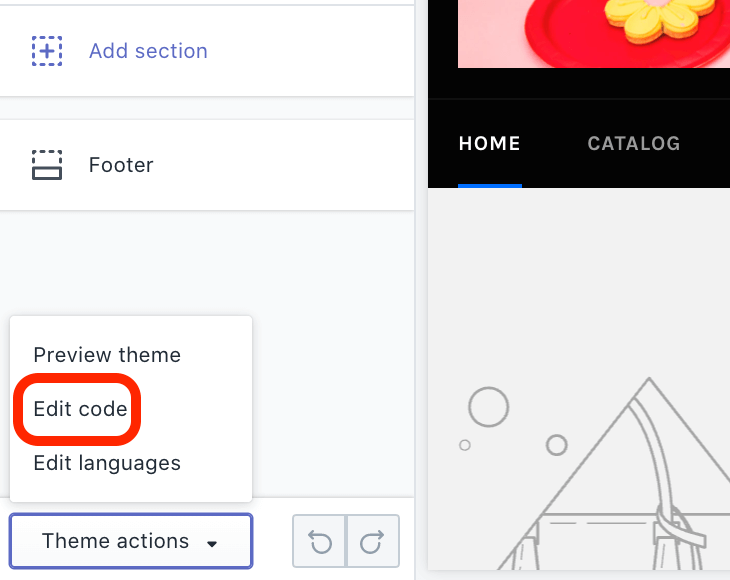
A new window will open, displaying your theme’s code templates to find the file that generates your collection links. In our case, we opened the Snippets folder and clicked on “{/} product-card.liquid” to locate the code we needed to edit. It appears on line 11, as indicated below. 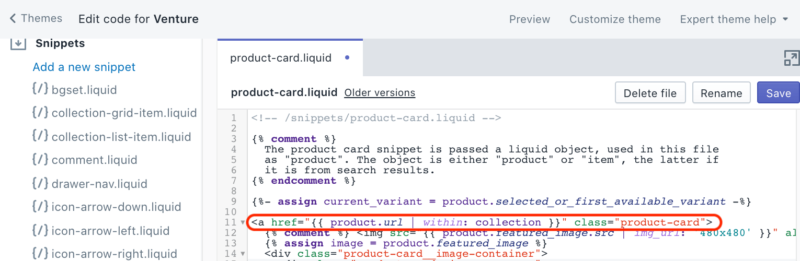
You’ll need to edit that line of code from:
To:
This can be done by deleting the “ | within: collection” portion of the code. Older Liquid theme templates make reference to the now-deprecated current_collection which matches the solution in the forum link provided above. The important thing to find is the “|” pipe to the “within” filter name to Shopify’s collections and remove it. The “within” filter builds the product link as part of the collection in the current collection context by switching what would otherwise be a rails route of “/products/:id” to “/collections/collection-name/products/:id,” for example. Since what we want is for such snippets to build links only to canonical URLs for the product, we simply remove the whole “within” filter and it works. Overcome site architecture limitationsAnother nagging problem associated with Shopify’s CMS is that your site architecture is part of the rigid structure of the Shopify rails implementation. The Shopify CMS is less flexible than WordPress, for example. If you want to perform seemingly straightforward optimizations to your site architecture, there isn’t always an obvious way to do so. 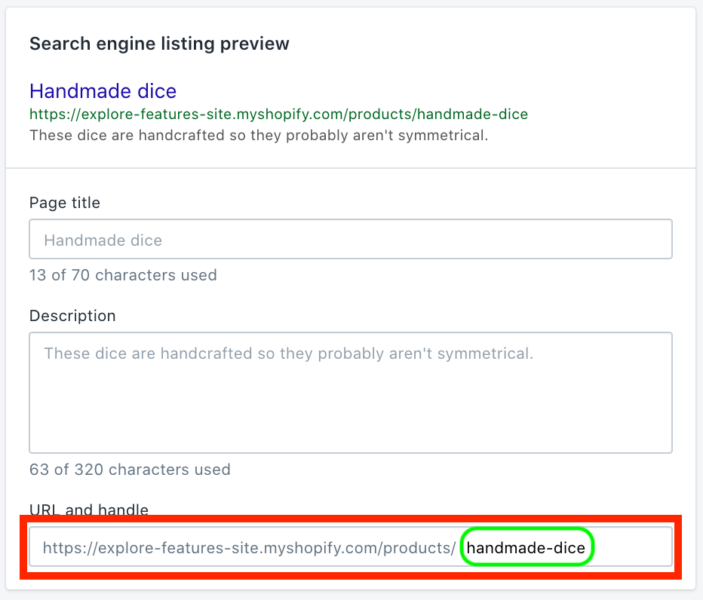
For example, Shopify automatically generates the URL for your product detail pages using the following structure: myshopifystorename.com/products/product-name. Store owners can only customize the last part of the URL (indicated in green), which is derived from the page title. If you want to remove the “/products” directory to tidy up your URLs, Shopify doesn’t have that option out-of-the-box. The SEO benefit of clean URLs is that users may be more inclined to click through from the search results, and other webmasters might be more likely to link to URLs which seem more authoritative by design. URLs with a path to a base directory page insinuate authority by virtue of a first-place directory rank and “/products” interferes with this. However, these paths are vital for your Shopify site’s backend to produce its dynamic content. Fortunately, there is an external workaround for this limitation. The problem arises with conventional system frameworks, which often utilize request strings for organizational logic to access varying resources so that differing templates are provided the resources they need for publishing dynamic page content and or services. In Shopify’s case, it’s Ruby on Rails routing convention, where “/products/:id” maps URLs to product resources. We’ve now tread into territory where you might be better off contacting a web developer unless you know how to write JavaScript and Ruby. These are more complex fixes for certain technical SEO problems that only a developer should implement. Customizing site architecture with Cloud Workers. Using Cloud Workers from caching solution providers can allow for alternate delivery paths and even deliver alternate resources for requests. Cloud Workers can effectively mask Shopify’s “/products” and “/pages” URL paths. With JavaScript Workers in the cloud, you have greater control over what’s available to you at the request/response cycle, which can mean control over practically anything. Examples include capturing requests for your sitemap.xml and robots.txt and serving alternate resources on-the-fly, injecting JavaScript into a page or groups of pages, and also cleaning up those pesky Shopify URLs to make keywords more prominent and pathnames more authoritative. You would need to own a domain for this to work and have your registrar reset its domain name system (DNS) to point to Cloudflare, which can then provide you with the JavaScript Workers API at the point where your end-users are directed through Cloudflare by proxy to your origin server. 
When you sign up for Cloudflare, you’ll log in and need to add DNS A records as well as collect Cloudflare nameserver addresses for use with your domain name registrar. Look for the DNS button as depicted above to get to the form for collecting the nameserver addresses and entering your website host IP address, where your website code is published. 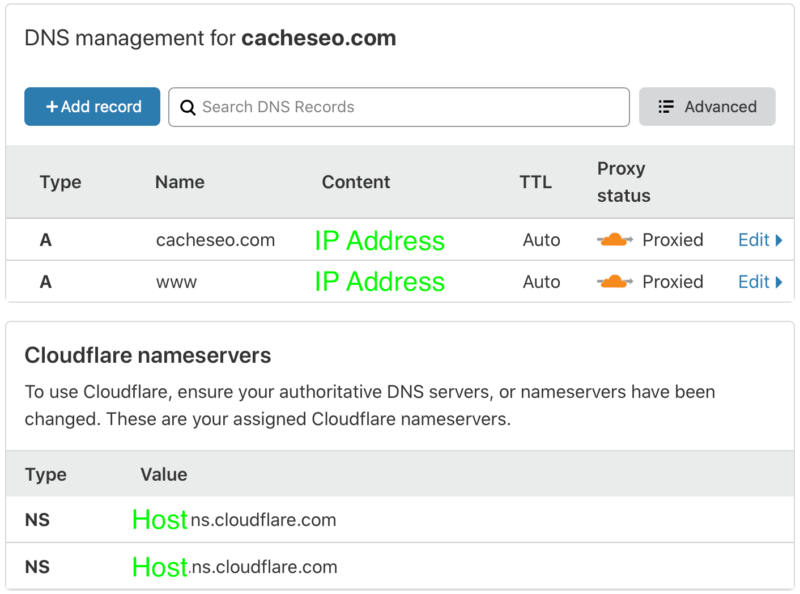
You add your host provider’s origin server IP addresses by adding DNS ‘A’ (Authority) records using the interface as shown above (highlighted in green), and the Cloudflare nameserver addresses for use at your domain registrar (again, highlighted in green) which you will need to enter into name server fields at your registrar. JavaScript Cloudflare Workers. Sign up for Cloudflare’s Workers and you now have access to introduce complex JavaScript for all manner of things. Configure which pages you want to begin managing with Workers by matching wildcard criteria to request URL structures, and you are then empowered with request and response objects to code against. The following example would direct all conceivable URLs, including subdomains for the domain, through a Worker API at Cloudflare by proxy. 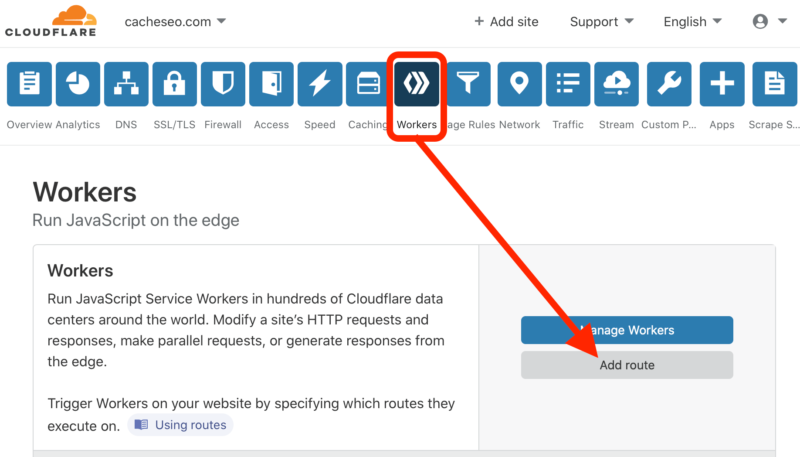
By clicking Workers and then the Add route button, you will be presented with a popup with the form for entering your URL route matching criteria. A wildcard syntax, which is the only dynamic matching operator you get, and being able to match several routes using the interface should be sufficient to match whatever you want. Refine your strategies to one route at a time since you can add several directed to one of several scripts. 
Cloudflare has you set up a subdomain.workers.dev address for hosting your Workers script. You get an editing interface and a preview playground as an IDE directly in the Cloudflare front end. You’ll be able to change HTTP verbs and test how your Worker script responds before going live. Solutions for things can run the gamut, from customizing response headers, Server Side Rendering (SSR), changing SEO by modifying titles, meta data, and content, redirecting, or even serving content from other hosts. In this way, you are enabled to perform SEO and/or full site migrations, including changes to architecture such as respelling “/pages” and “/products.” This example demonstrates a few of these possibilities. 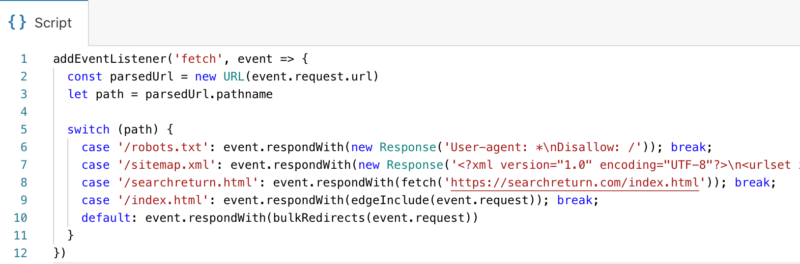
While there are references to other blocks and line 7 is incomplete, this block will parse a URL from the request object assigning it to the variable named “path,” and use it in a JavaScript switch statement to serve robots.txt and sitemap.xml Response objects, writing them directly without hitting the origin server at all. In the case of one particular request designated on line 8, it will serve a page from another domain instead, and before a fall-through default, line 9 will insert an include with the home page. This example should provide you with a lot of food for thought about solving problems, including what you can do for Shopify issues. However, Cloudflare isn’t currently offering this as a self-service product for Shopify sites just yet, but it will after an initial testing period. The service has been live for over a year available to non-Shopify sites. “The issue was that previously our system did not allow a direct customer to proxy in front of another customer, e.g., if you went to cloudflare.com and signed up yourstore.com as a zone, we used to block you from proxying [with Shopify] for various technical reasons,” Patrick Donahue, director of product management at Cloudflare, told Search Engine Land. Cloudflare’s enterprise sales team is currently working directly with Shopify merchants who want to onboard because there are manual steps involved that require assistance from their solutions engineers, Donahue explained. Cloudflare plans to make this option more widely available later this year. More solutions may be on the horizon. Now that Cloudflare has solved the problem of sorting out the proxy configuration settings to get it to work with Shopify (which itself uses a caching solution), hopefully other caching solution providers will offer similar services as Cloudflare is preparing to with Shopify stores. Looking for more ways to optimize and market your Shopify store?Check out these resources:
More development tips for SEOsThe post Technical SEO for Shopify: A guide to optimizing your store for search engines appeared first on Search Engine Land. via Search Engine Land https://ift.tt/3esNK5E There is an old misconception that Facebook Marketplace is still only a C2C platform similar to Craigslist. That is no longer true. In its initial stages, Facebook Marketplace was only offering individual users the opportunity to list and purchase items locally. As the Marketplace grew in popularity, Facebook added new features, like the ability to process a transaction through checkout, and the option to offer shipping. Now, Facebook Marketplace is open to US-based businesses selling new products. According to Facebook’s internal data from 2019, one out of three Facebook users also utilize Facebook Marketplace, which means there is a major B2C opportunity for US retailers. Here are four reasons why sellers should get a jump on Facebook Marketplace. 1. Facebook Marketplace has low selling feesWith commission rates of 5% or a minimum of $0.40 for transactions under $8.00, Facebook currently offers some of the lowest selling fees among marketplaces. As of today, the commission rates do not change based on product category, unlike other major marketplaces. On Facebook Marketplace, there are also no listing fees, which means you can upload unlimited inventory, and there are no subscription fees or tiered selling plans for signing up as a retailer. As marketplaces grow in popularity, they tend to increase their commission rates. Amazon’s recent increase from 15% to 17% for apparel categories is a prime example (pun intended). Although Facebook has given no indication that they intend to increase their commission rates in the future, supply and demand dictates that it’s better to get in early. We highly recommend establishing a strong seller history now, when commission rates are low. 2. Getting on Facebook Marketplace can be a simple transitionSince the B2C opportunity on Facebook Marketplace is still in beta, you must meet certain criteria in order to list on Marketplace. Facebook prefers that retailers work with an approved listing partner, like Feedonomics, to get their items on the Marketplace. This is because listing partners have already gone through the onboarding process several times and have contacts at Facebook who can help with any tricky situations. The onboarding process consists of the usual marketplace setup: input your business information, adjust your shipping and tax settings, link accounts for payments, and select your data feed source. My company has been helping many clients get live on Facebook Marketplace, and the timeframe for going live on Facebook Marketplace usually depends on how quickly a merchant can provide the information above. 
If you already use data feeds to list ads on Facebook or Google Shopping, then transitioning to Facebook Marketplace is fairly simple. Typically, the main additional requirement for selling on a marketplace is that you include your inventory quantities in your feed. It’s important to create inventory rules that prevent you from overselling products that exist on multiple marketplaces. In a Facebook Marketplace case study, the e-commerce company Daily Steals opted into deals on Facebook and ran a promotion on their Sony PS4 controllers. They reached 6.4 million people and had a 5x faster sales rate than similarly-priced deals that were not promoted on the Marketplace. To see if Facebook checkout resulted in more conversions, they conducted a split test, and found that shoppers converted twice as often if they used checkout directly through the Facebook app, compared to going through checkout on their website. If you are somebody who already runs ads on Facebook, note that Facebook Marketplace will need to use your child-level SKU as the product identifier. This is because a successful order integration requires a child-level SKU to be associated with a customer’s order. When it comes to product ads, merchants may often choose to use parent-level IDs for Pixel tracking—this makes sense when you want to show a display ad for a parent product, instead of showing an ad for every size of a product. However, when listing your products on a marketplace, using child-level product identifiers is the only way to make sure your order integration links to the correct product data for fulfillment. 3. Facebook Marketplace is a package dealListing your inventory on Facebook Marketplace opens the door to using the same catalog for checkout on Instagram. Instagram and Facebook are the two most widely-used social media networks in the US, and the 5% commission rate stays the same across both apps. This can give you access to significantly different audiences, without requiring much additional setup on the integration side. According to the Pew Research Center, Instagram captures a younger demographic and Facebook trends toward an older demographic, with significant overlap in the middle. Before you list your products on both sites, consider which channel fits in with your business strategy. Instagram Shopping does require more curating, since the products are primarily promoted through the creation of shoppable posts; if you have a strong visual focus and social media resources, you can be very successful on Instagram. You have the ability to opt-in only your best sellers on Instagram, to make sure you’re being efficient with your posting. While the integration is fairly simple, the strategy for selling with checkout on Instagram should be different. 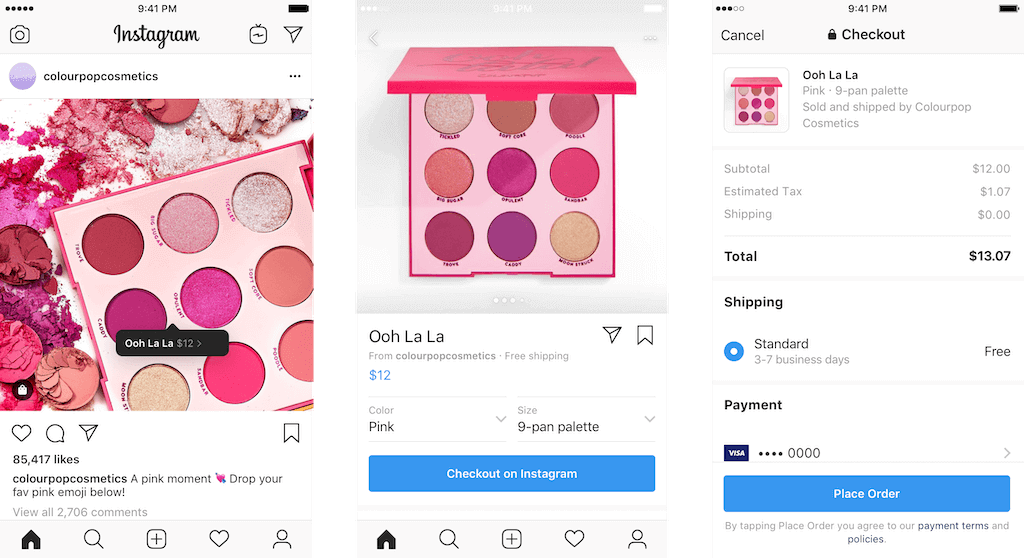
However, if you don’t feel as social media savvy, Facebook Marketplace has the infrastructure to handle most of the product exposure for you, as explained below. Facebook Marketplace is a little more “set it and forget it” than Instagram – though we’d never recommend a “set it and forget it” approach for ad campaigns or data feeds in general. 4. Facebook has the ability to make shopping highly personalizedFacebook uses the data about its users to help connect them to products that they’ll like. As a user interacts with Facebook Marketplace over time, customers will experience a more tailored feed based on variables such as products that their interests or what they’ve clicked on. This results in a data-based, personalized shopping experience, where the products find the customers. Your products on Facebook will show up in multiple places – Newsfeed, Marketplace and Page Shops. Newsfeed listings appear between posts, as suggested products. Marketplace listings will appear among other Marketplace products, but each user will be shown the products that they are likely to purchase. Because of this, no two users will have the same Marketplace feed. A Page Shop will show all your products grouped together, in what is classically considered a store. The Page Shop will make your products visible when a customer uses the Marketplace and browses through the “Stores,” and will allow customers to purchase products directly from your Facebook page. In a Facebook Marketplace case study, the e-commerce company Succulents Box saw a 66% average increase in total purchases after listing their products on the Marketplace. They found that Facebook’s targeting brought new audiences and increased engagement on their Page. They also saw a 19% average increase in monthly revenue from Marketplace. If you have a Facebook Business Page, you will be able to set up a Facebook Page Shop. It’s relatively easy. 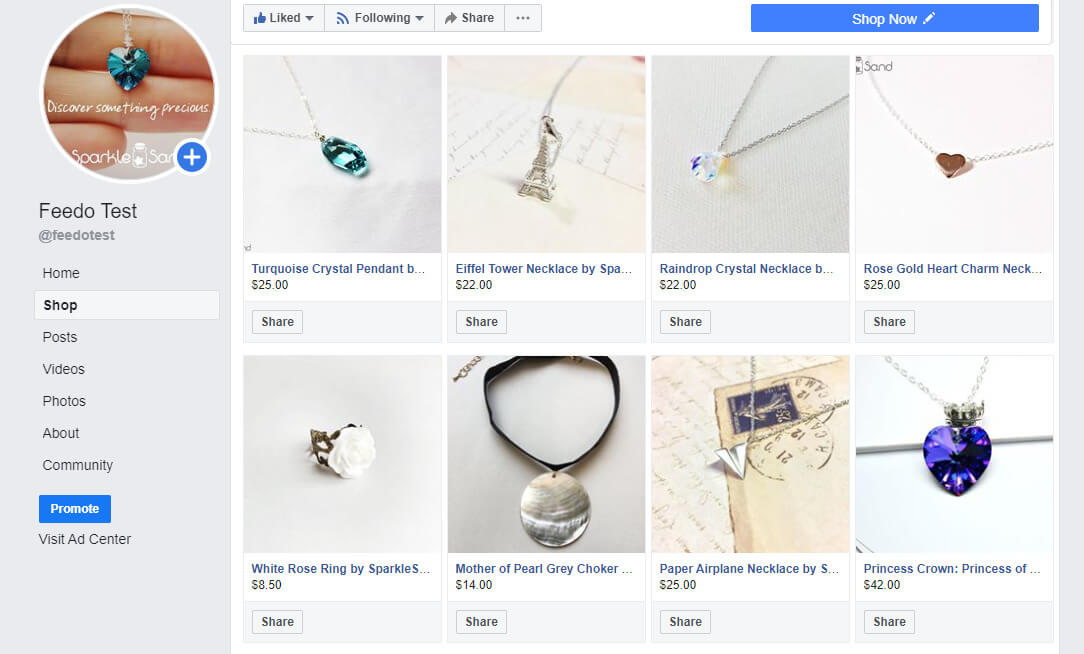
You will need to be logged onto a computer, then go to your Facebook page and click the Shop tab. From there, you will be directed to your Commerce Manager, where you will need to link your accounts, set up your business policies, and set up payouts. Once you link your catalog and publish it, you should be good to go! There is also an additional beta program in the works. Select sellers will be able to utilize the checkout function for their Dynamic Product Ads and Instagram Shopping ads. Essentially, customers will be able to click on a product ad and then checkout directly from the ad. Combining the visual features of Facebook’s Creative Hub, the targeting ability of DPAs, and the frictionless experience of checkout will give you a lot of potential to convert quickly. The post Facebook Marketplace is open for businesses selling new products appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2M3tVFZ Starting today, Google is beginning the first phase of its program to provide $340 million in Google Ads advertising credits for eligible small and medium-sized businesses. Qualifying advertisers in New Zealand will be the first recipients of this program. Advertisers that qualify will be notified and see the credit to be used for future advertising in their Google Ads accounts. How much? Google also has provided more information about the amount of the credits. The amount will vary by advertiser, based on historical spend, up to a maximum of $1,000 US dollars (or the equivalent in the currency of the account). Advertisers will receive one credit and have until December 31 to use it, after which it will expire. Why is this being phased in? Google has long had a coupon program for new advertisers, but the company had to build a new product and infrastructure to support this credit program. The phasing process will help ensure a smooth rollout for the new system. Google says that, after starting with New Zealand, it aims to roll out credits over the next several weeks. To be eligible. This program is intended to support existing, dedicated advertisers who have been affected by the COVID-19 crisis. To be eligible for an ad credit, you will need to have run Google Ads campaigns in 10 out of 12 months in 2019 and in either January and/or February of 2020. It doesn’t matter if the campaigns were run in Google Ads account directly or through a partner. There is no way to apply to this program. Why we care. The credits are designed to be used to help SMBs start to re-engage customers in the coming months. The COVID-19 crisis has severely affected small businesses, and these credits are part of a larger effort to support this important customer base. Earlier today, the company introduced Google My Business features aimed at helping SMBs adapt and survive the crisis. For example, business owners globally can now add donation and gift card links to business profiles, through Google partnerships with PayPal and GoFundMe. For more on the ads credit program, see the help center page. Related:
More about marketing in the time of the coronavirusThe post Google Ads credits for SMBs start rolling out appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2A9fUnv The crawling and indexing processes lay the groundwork for search engines to rank results. Despite being fundamental aspects of how search engines operate, crawling and indexing are often overlooked or misunderstood. During our crawling and indexing session of Live with Search Engine Land, Martin Splitt, search developer advocate at Google, explained these two processes using a simple analogy about librarians. “Imagine a librarian: If you are writing a new book, the librarian has to actually take the book and figure out what the book is about and also what it relates to, if there’s other books that might be source material for this book or might be referenced from this book,” Splitt said. In his example, the librarian is Google’s web crawler (referred to as Googlebot) and the book is a website or webpage. “Then you . . . have to read through [the book], you have to understand what it is about, you have to understand how it relates to the other books, and then you can sort it into the catalog,” he said, explaining the indexing process. The content of your webpage is then stored in the “catalog” (i.e., the search engine’s index), where it can be ranked and served as a result for relevant queries. To bring the analogy full circle, Splitt also described the process in technical terms: “We have a list of URLs . . . and we take each of these URLs, we make a network request to them, then we look at the server response and then we also render it (we basically open it in a browser to run the JavaScript) and then we look at the content again, and then we put it in the index where it belongs, similar to what the librarian does.” Why we care. For content to be eligible to appear in search results, it must first be crawled and indexed. Understanding how crawling and indexing work can help you resolve technical SEO issues and ensure your pages are accessible to search engines. Want more Live with Search Engine Land? Get it here:
The post How Google crawls and indexes: a non-technical explanation [Video] appeared first on Search Engine Land. via Search Engine Land https://ift.tt/3gzOjwH Looking for creative ways to adapt search to new digital experiences? Wondering what tools can help remedy a drop in rankings? Eager to leverage new technologies to enhance e-commerce experiences? Join thousands of your peers online (for free!), June 23-24, for SMX Next to learn innovative SEO and SEM tactics that can help you achieve these and many more search marketing initiatives! Don’t miss the opportunity to learn from T-Mobile, Procter & Gamble, Macy’s, and more – for free – all without leaving your desk (or couch!): 
You’ll also train with search marketing technology experts from Microsoft, Bruce Clay, Moz, Botify, and loads more. I’ll reach out again when the agenda is live and ready for you to explore. Register now to access 40+ expert-led sessions that will equip you with actionable tactics that can help drive more traffic, leads, and sales. We’re happy to deliver a virtual SMX experience you can enjoy from the comfort and safety of your home. But sadly, not everyone lives in a comfortable or safe environment. That’s why we’re taking this opportunity to donate to New Beginnings, a Seattle-based organization that supports and empowers victims of domestic abuse. We hope you’ll consider donating, too. The post Learn actionable tactics from search marketing experts – free! appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2ZHa0Vn Core Web Vitals report replaces Speed report in Google Search Console: What you need to know5/27/2020 Google has quietly swapped out the speed report in Google Search Console with the new Core Web Vitals report. If you are trying to find the speed report, don’t panic, it has just changed names and is using the new web vitals engine to power it. Core Web Vitals in Search Console. When you login to Google Search Console, Google will show you a notice about this new report: 
This is what the report looks like; yes, it looks pretty similar to the speed version. Google has not announced what has changed exactly with this report, but it does show different metrics. Here is what it looks like now: 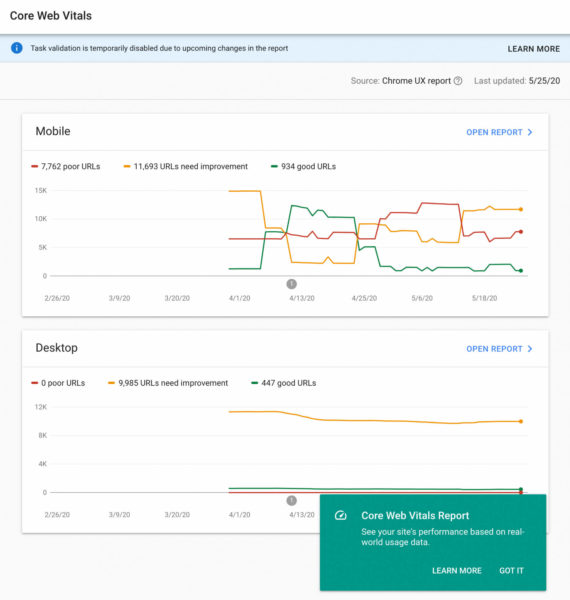
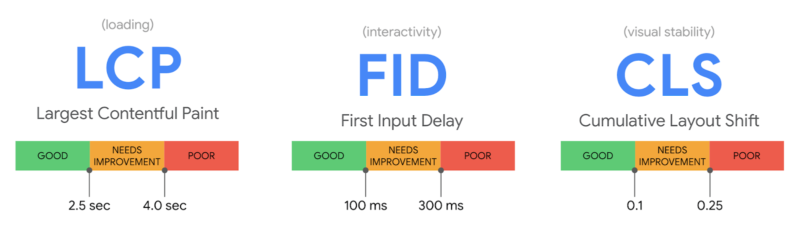
What are core web vitals? It is a new set of metrics Google introduced earlier this month. Google defines it as “the subset of Web Vitals that apply to all web pages, should be measured by all site owners, and will be surfaced across all Google tools. Each of the Core Web Vitals represents a distinct facet of the user experience, is measurable in the field, and reflects the real-world experience of a critical user-centric outcome.” The current set of core web vitals for 2020 focuses on three aspects of the user experience—loading, interactivity, and visual stability—and includes the following metrics (and their respective thresholds):
LCD, FID and CLS. Here are the thresholds for largest contentful paint, first input delay and cumulative layout shift:
More details. Google has a new help document for this specific report. Google said that this report is based on three metrics: LCP, FID, and CLS. If a URL does not have a minimum amount of reporting data for any of these metrics, it is omitted from the report. Once a URL has a threshold amount of data for any metric, the page status is the status of its most poorly performing metric. Why we care. This report should help you improve the overall speed and performance of your web site. Google will continue to add and modify these metrics and give you automated feedback on your sites performance. Use these reports as tips on where you can focus on to make small but yet larger performance improvements to your web site. The post Core Web Vitals report replaces Speed report in Google Search Console: What you need to know appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2XCDyAH |
Archives
April 2024
Categories
|
