INTERNET MARKETING SUCCESS

|
Working remotely certainly has its benefits. Besides undeniable autonomy and supreme flexibility, the daily commute becomes drastically shorter. However, starting to work from home also introduces a number of potential issues. It takes quite a lot of practice to avoid the most common pitfalls. Keeping regular work hours is challenging, […]
via Lawrence Tam https://ift.tt/2YluG4q
0 Comments
On Friday, I will moderate our next Live with Search Engine Land discussion on brand vs. performance marketing during COVID-19. We’ll discuss whether marketers should be focusing on top-of-funnel awareness campaigns and less on the bottom-of-the-funnel during this tumultuous period. With reduced budgets and pressure to justify spend and hit sales targets, marketers often default to “more measurable,” performance-based campaigns. Brand campaigns are seen as softer, longer term and less measurable than bottom-of-the-funnel tactics. The panel will discuss why that thinking could result in missed opportunities. The panel will feature:
Our experts will share their current experiences and what they’re seeing in the market in real time. We’ll discuss B2B, B2C, content, commerce and which channels are best performing right now. The panelists will also talk about how current trends are likely to play out after the crisis is over. The conversation will happen at 2 p.m. EST (11 a.m. PDT) this Friday, May 1. It will be live-streamed on Search Engine Land and on our YouTube channel. We at Search Engine Land know there is so much uncertainty now in our community, and we hope this series of live discussions, presentations, tutorials and meetups help everyone stay sharp and up to date on tactics and best practices. We do not plan to gate these sessions. This isn’t about leads for us. This is about giving great marketers a platform to inform, support and convene our global community at a time when so much is up in the air, including livelihoods. If you have an idea for a session or would like to join a panel, email our VP of Content Henry Powderly. In the meantime, check out our most recent chat (on content) below. The post Up next on Live with Search Engine Land: Should you go all-in on brand marketing now? appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2SdEtWn 
I have run into an interesting robots.txt situation several times over the years that can be tricky for site owners to figure out. After surfacing the problem, and discussing how to tackle the issue with clients, I find many people aren’t even aware it can happen at all. And since it involves a site’s robots.txt file, it can potentially have a big impact SEO-wise. I’m referring to robots.txt files being handled by subdomain and protocol. In other words, a site could have multiple robots.txt files running at the same time located at www and non-www, or by protocol at https www and http www. And since Google handles each of those separately, you can be sending very different instructions about how the site should be crawled (or not crawled). In this post, I’ll cover two real-world examples of sites that ran into the problem, I’ll cover Google’s robots.txt documentation, explain how to detect this is happening, and provide several tips along the way based on helping clients with this situation. Let’s get crawling, I mean moving. :) Robots.txt by subdomain and protocol I just mentioned above that Google handles robots.txt files by subdomain and protocol. For example, a site can have one robots.txt file sitting on the non-www version, and a completely different one sitting on the www version. I have seen this happen several times over the years while helping clients and I just surfaced it again recently. Beyond www and non-www, a site can have a robots.txt file sitting at the https version of a subdomain and then also at the http version of that subdomain. So, similar to what I explained above, there could be multiple robots.txt files with different instructions based on protocol. Google’s documentation clearly explains how it handles robots.txt files and I recommend you read that document. Here are some examples they provide about how robots.txt instructions will be applied: 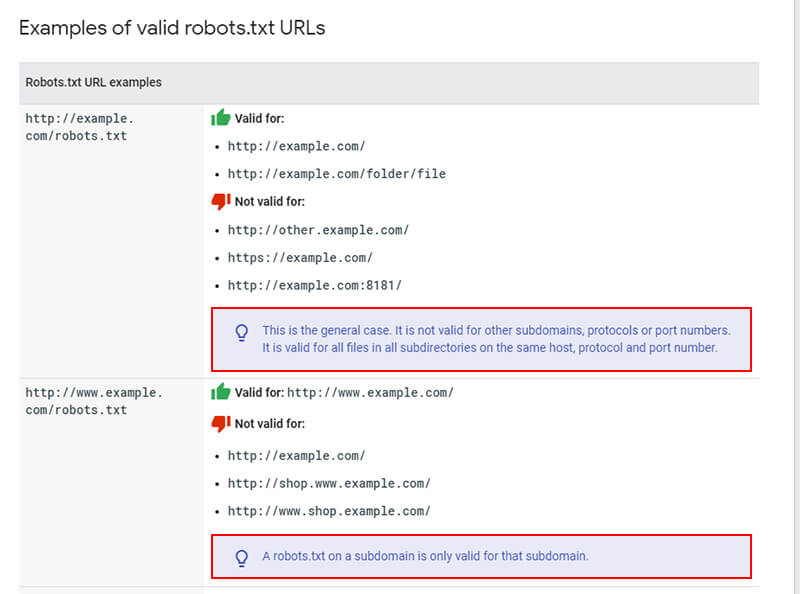
This can obviously cause problems as Googlebot might fetch different robots.txt files for the same site and crawl each version of the site in different ways. Googlebot can end up doing some interesting things while site owners incorrectly believe it’s following one set of instructions via their robots.txt file, when it’s also running into a second set of instructions during other crawls. I’ll cover two cases below where I ran into this situation. Case study #1: Different robots.txt files with conflicting directives on www and non-www While performing a crawl analysis and audit recently on a publisher site, I noticed that some pages being blocked by robots.txt were actually being crawled and indexed. I know that Google 100% obeys robots.txt instructions for crawling so this was clearly a red flag. And to clarify, I’m referring to URLs being crawled and indexed normally, even when the robots.txt instructions should be disallowing crawling. Google can still index URLs blocked by robots.txt without actually crawling them. I’ll cover more about that situation soon. When checking the robots.txt file manually for the site, I saw one set of instructions on the non-www version which were limited. Then I started to manually check other versions of the site (by subdomain and protocol) to see if there were any issues. And there it was, a different robots.txt file was sitting on the www version of the site. And as you can guess, it contained different instructions than the non-www version. non-www version of the robots.txt file: 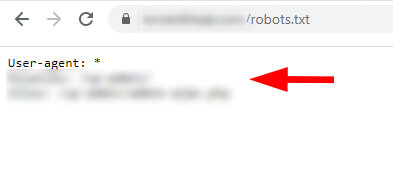
www version of the robots.txt file: 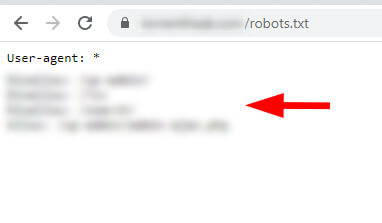
The site was not properly 301 redirecting the www version of the robots.txt file to the non-www version. Therefore, Google was able to access both robots.txt files and find two different sets of instructions for crawling. Again, I know that many site owners aren’t aware this can happen. A quick note about pages blocked by robots.txt that can be indexed I mentioned earlier that pages properly blocked by robots.txt can still be indexed. They just won’t be crawled. Google has explained this many times and you can read more about how Google can index robotted URLs in its documentation about robots.txt. I know it’s a confusing subject for many site owners, but Google can definitely still index pages that are disallowed. For example, Google can do this when it sees inbound links pointing to those blocked pages. When that happens, it will index the URLs and provide a message in the SERPs that says, “No information can be provided for this page”. Again, that’s not what I’m referring to in this post. I’m referring to URLs that are being crawled and indexed based on Google seeing multiple versions of a robots.txt file. Here is a screenshot from Google’s documentation about robotted URLs being indexed. 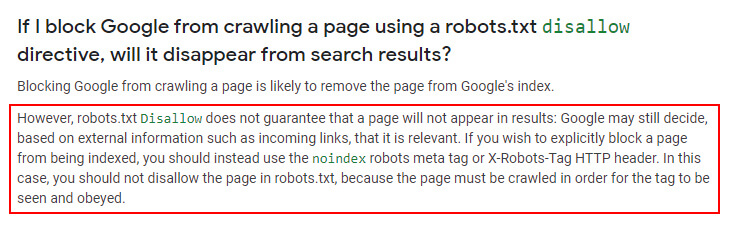
What about Google Search Console (GSC) and robots.txt files? In a faraway region of Google Search Console, where search tumbleweeds blow in the dusty air, there’s a great tool for site owners to use when debugging robots.txt files. It’s called the robots.txt Tester and it’s one of my favorite tools in GSC. Unfortunately, it’s hard for many site owners to find. There are no links to it from the new GSC, and even the legacy reports section of GSC doesn’t link to it. When using that tool, you can view previous robots.txt files that Google has seen. And as you can guess, I saw both robots.txt files there. So yes, Google was officially seeing the second robots.txt file. robots.txt Tester in GSC showing one version: 
robots.txt Tester in GSC showing the second version: 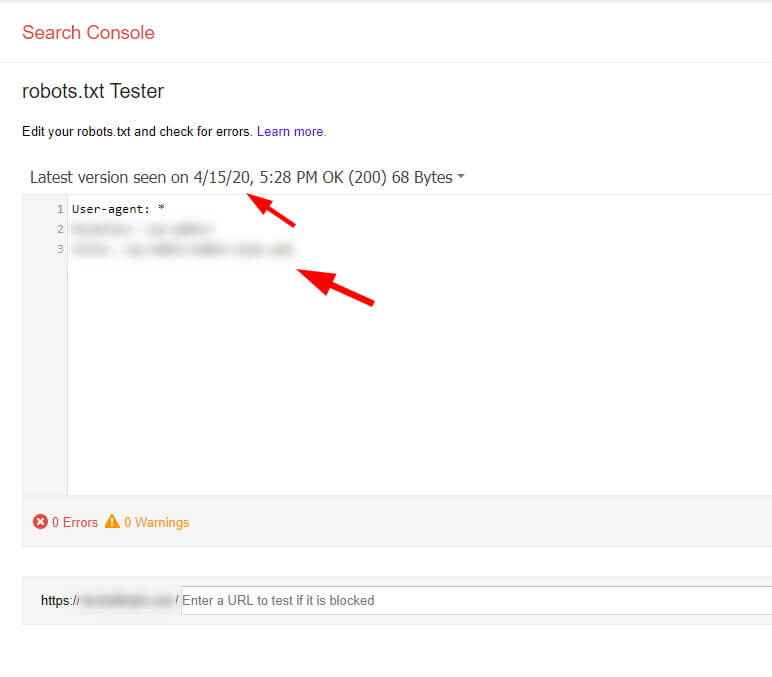
Needless to say, I quickly emailed my client with the information, screenshots, etc., and told them to remove the second robots.txt file and 301 redirect the www version to the non-www version. Now when Google visits the site and checks the robots.txt file, it will consistently see the correct set of instructions. But remember, there are some URLs incorrectly indexed now. So, my client is opening those URLs up for crawling, but making sure the files are noindexed via the meta robots tag. Once we see that total come down in GSC, we’ll include the correct disallow instruction to block that area again. Case study #2: Different robots.txt files for http and https and a blanket disallow As a quick second example, a site owner contacted me a few years ago that was experiencing a drop in organic search traffic and had no idea why. After digging in, I decided to check the various versions of the site by protocol (including the robots.txt files for each version). When attempting to check the https version of the robots.txt file, I first had to click through a security warning in Chrome. And once I did, there it was in all its glory… a second robots.txt file that was blocking the entire site from being crawled. There was a blanket disallow in the https version of the robots.txt file. For example, using Disallow: / Note, there were a number of other things going on with the site beyond this issue, but having multiple robots.txt files, and one with a blanket disallow, was not optimal. The https robots.txt file (hidden behind a security warning in Chrome): 
Site health problems showing in GSC for the https property: 
Fetching the https version shows it was blocked: 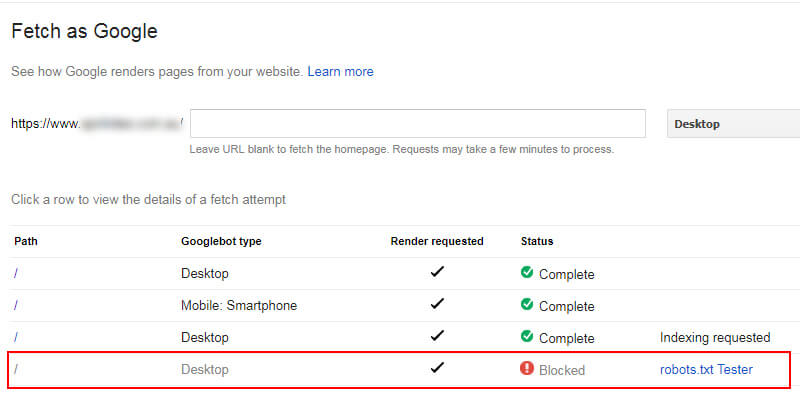
Similar to the first case, the site owner moved quickly to rectify the problem (which was no easy feat based on their CMS). But they eventually got their robots.txt situation in order. It’s another great example of how Google treats robots.txt files and the danger of having multiple files by subdomain or protocol. Tools of the trade: How to detect multiple robots.txt files by subdomain or protocol To dig into this situation, there are several tools that you can use beyond manually checking the robots.txt files per subdomain and protocol. The tools can also help surface the history of robots.txt files seen across a site. Google’s robots.txt Tester I mentioned the robots.txt Tester earlier and it’s a tool directly from Google. It enables you to view the current robots.txt file and previous versions that Google has picked up. It also acts as a sandbox where you can test new directives. It’s a great tool, even though Google is putting it in a distant corner of GSC for some reason. 
The wayback machine Yes, the internet archive can help greatly with this situation. I’ve covered this in a previous column on Search Engine Land, but the wayback machine is not just for checking standard webpages. You can also use it to review robots.txt files over time. It’s a great way to track down previous robots.txt versions. 

The fix: 301 redirects to the rescue To avoid robots.txt problems by subdomain or protocol, I would make sure you 301 redirect your robots.txt file to the preferred version. For example, if your site runs at www, then redirect the non-www robots.txt to the www version. And you should already be redirecting http to https, but just make sure to redirect to the preferred protocol and subdomain version. For example, redirect to https www if that’s the preferred version of your site. And definitely make sure all URLs are properly redirected on the site to the preferred version. 
For other subdomains, you might choose to have separate robots.txt files, which is totally fine. For example, you might have a forum located at the subdomain forums.domain.com and those instructions might be different from www. That’s not what I’m referring to in this post. I’m referring to www versus non-www and http versus https for your core website. Again, other subdomains could absolutely have their own robots.txt files. Summary: For robots.txt files, watch subdomain and protocol Since it controls crawling, it’s incredibly important to understand how Google handles robots.txt files. Unfortunately, some sites could be providing multiple robots.txt files with different instructions by subdomain or protocol. And depending on how Google crawls the site, it might find one, or the other, which can lead to some interesting issues with crawling and indexing. I would follow the instructions, pun intended, in this post to understand how your site is currently working. And then make sure you are sending the clearest directions possible to Googlebot for how to crawl your site. The post Mixed Directives: A reminder that robots.txt files are handled by subdomain and protocol, including www/non-www and http/https [Case Study] appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2KK55Ks Google My Business (GMB) is a core focus for local SEOs. It has also become the central locus of communication between businesses and consumers about store hours, closures, services and other information during the COVID-19 outbreak. Shifting engagement on GMB. Click and call data show that consumer engagement with GMB has changed significantly during the crisis, as people have shifted their buying behavior online and, although it varies considerably by category, away from physical business locations. As one example, the query “takeout near me” has spiked beyond “restaurant reservations” since shelter-in-place orders took effect. This remains a local query; what’s changed is the transaction (now, mostly online) and its fulfillment (pick-up/delivery). ‘Takeout near me’ vs. ‘restaurant reservations’ 
Directions, clicks, calls and reviews. Driving directions requests, as you might expect, have fallen off dramatically, but calls and website visits, driven by GMB, have not been impacted as much. New data from Reputation.com argues that “GMB driving-direction clicks are down 60% across all verticals.” Website clicks have decreased 31% and call clicks are down 21%. Other data I’ve seen show somewhat different numbers, but it’s safe to say that clicks have migrated away from driving directions to website visits and calls. In terms of GMB actions, Reputation.com also reports significant declines for retail, restaurants and automotive, but, more recently, there has been a modest recovery in consumer engagement. This may mirror an uptick in online shopping and e-commerce spending driven in part by stimulus checks and by a sense that we may be coming to the end of the lockdown period. GMB Clicks Breakdown: Directions, Calls, Websites 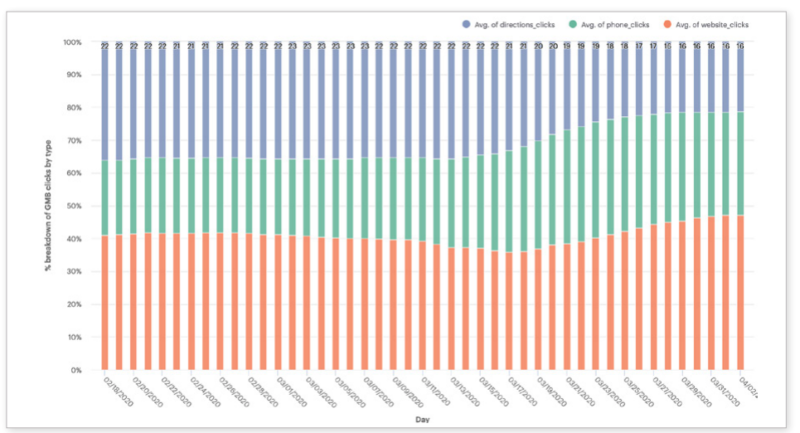
Reviews are something of a blind spot, given that Google had stopped publishing new reviews and business owner replies until recently. Now that reviews have come out of quarantine and are trickling back in, it will be interesting to see whether and how review patterns changed during the lockdown period. Post-pandemic, GMB will continue to be a local business lifeline. As businesses reopen, local marketers will once again turn to GMB to communicate about operating hours, products and service availability. And, it will likely emerge from COVID-19 an even more important marketing tool than it was before the pandemic. Local features such as Posts, which enabled businesses to more easily communicate timely updates with their customers, may gain wider adoption and new prominence. And, Google may accelerate the rollout of other tools in the pipeline. 
Sixty-eight percent of local marketing experts said GMB was more important now than it was a year ago, according to a survey by BrightLocal. Moz’s most recent Local Ranking Factors study concluded GMB signals were the top-ranking factor for the Google Local Pack and number four for local SEO. Among the many tasks to manage and monitor on GMB, growing reviews was considered by 87% in the BrightLocal survey to be the most important to local marketing success. Fighting spam (such as fake listings and illegitimate reviews) on Google was number two. Indeed, Google has a significant fake reviews problem that the company urgently needs to address in a sustained and vigorous way. Why we care. The next 12 months will likely see an acceleration of GMB’s evolution. Local search has always been about using digital tools and information to make purchase decisions offline. Over the long sweep of GMB’s evolution, it has grown from being a way to get content to Google into a dynamic channel mediating transactions between consumers and business owners. Post-COVID, we’re going to see a much tighter integration of digital tools (inventory, booking, ordering, payments) with offline fulfillment, further blurring the distinction between online and offline — reflected in Google’s acquisitions of TheOrdering.app and Pointy. These are examples of how Google is trying to bridge the digital-physical divide and how it continues to make itself indispensable, not just as a marketing channel, but increasingly as a kind of back-office platform for local business. The post GMB usage declines, but poised to become more powerful post-coronavirus appeared first on Search Engine Land. via Search Engine Land https://ift.tt/3cT29Hv The roughly 30 million small businesses (SMBs) in the U.S. employ nearly 48% of all workers according to the U.S. Small Business Administration. The bulk of SMBs are very small and highly vulnerable to failure in the wake of COVID-19 lockdowns. According to a Brookings analysis, 48 million small business jobs are at risk from a small business collapse. Another analysis asserts that as many as one third of all SMBs in the U.S. are at “risk of closure” over the next two to five months. SMB failures will impact digital agencies. Beyond the destruction of lives and communities, this matters to marketers because SMBs spend billions in the aggregate on marketing, a meaningful percentage of which flows through digital agencies. If there are large-scale small businesses failures — in the millions — that would have a very direct impact on agencies, SaaS platforms and martech companies that serve them. For example, the majority of Facebook’s 7 million active advertisers are small businesses. A new report out this morning from Yelp tries to quantify the impact of COVID-19 on small businesses. Using a variety of internal data from Yelp’s platform, the company says the economic impact of the pandemic has been “unlike anything” it has seen in its prior 15 years of existence. 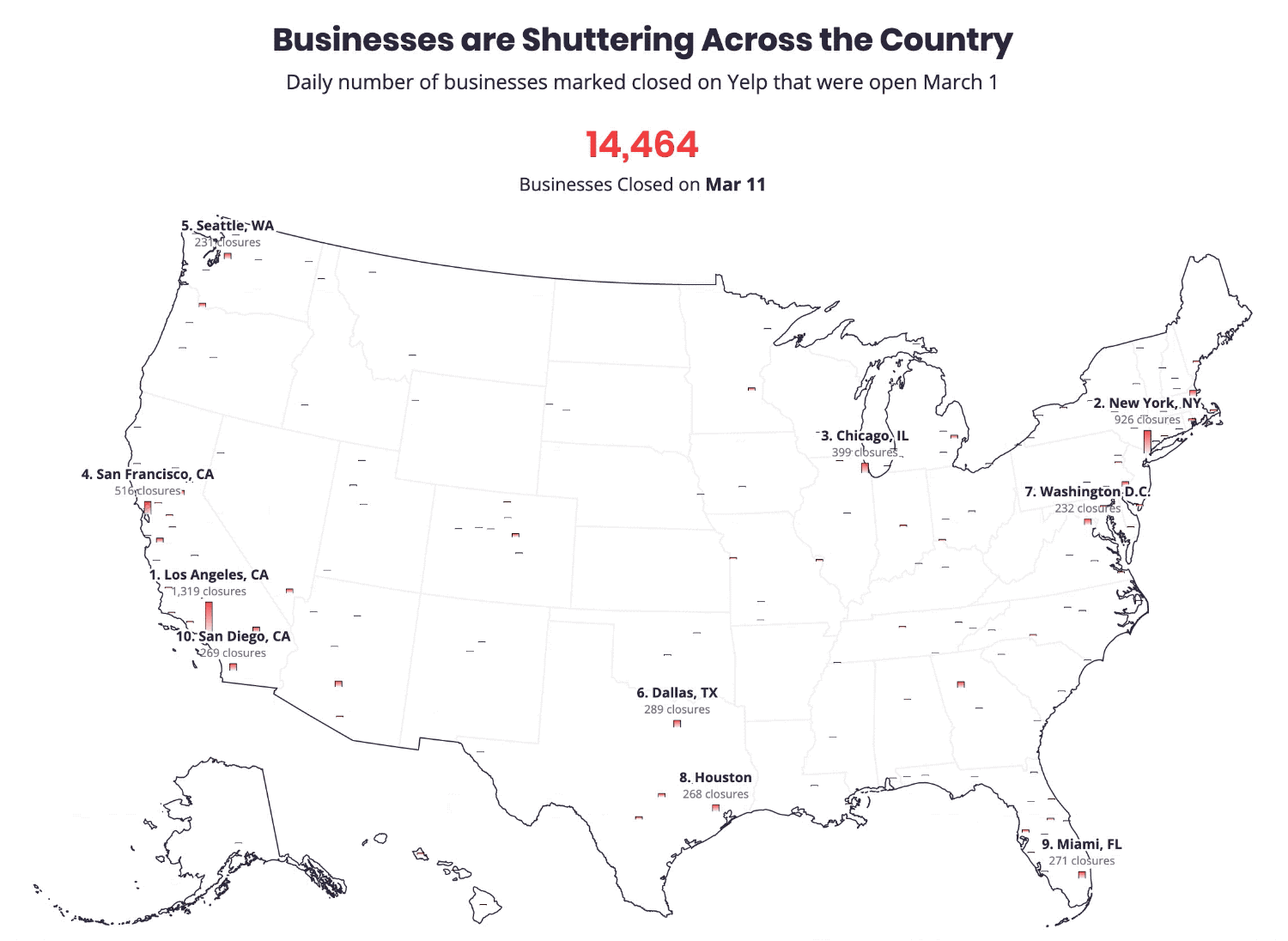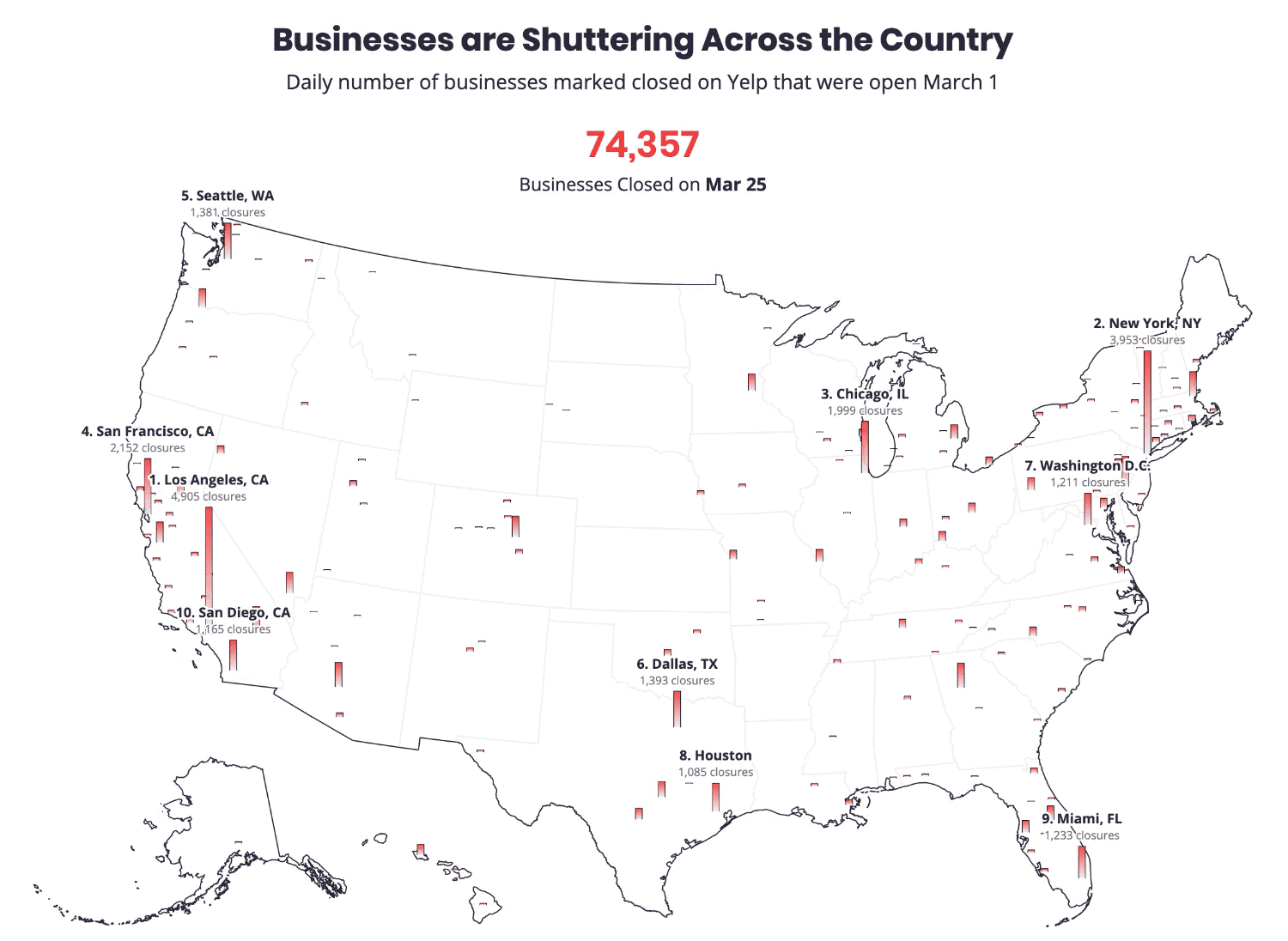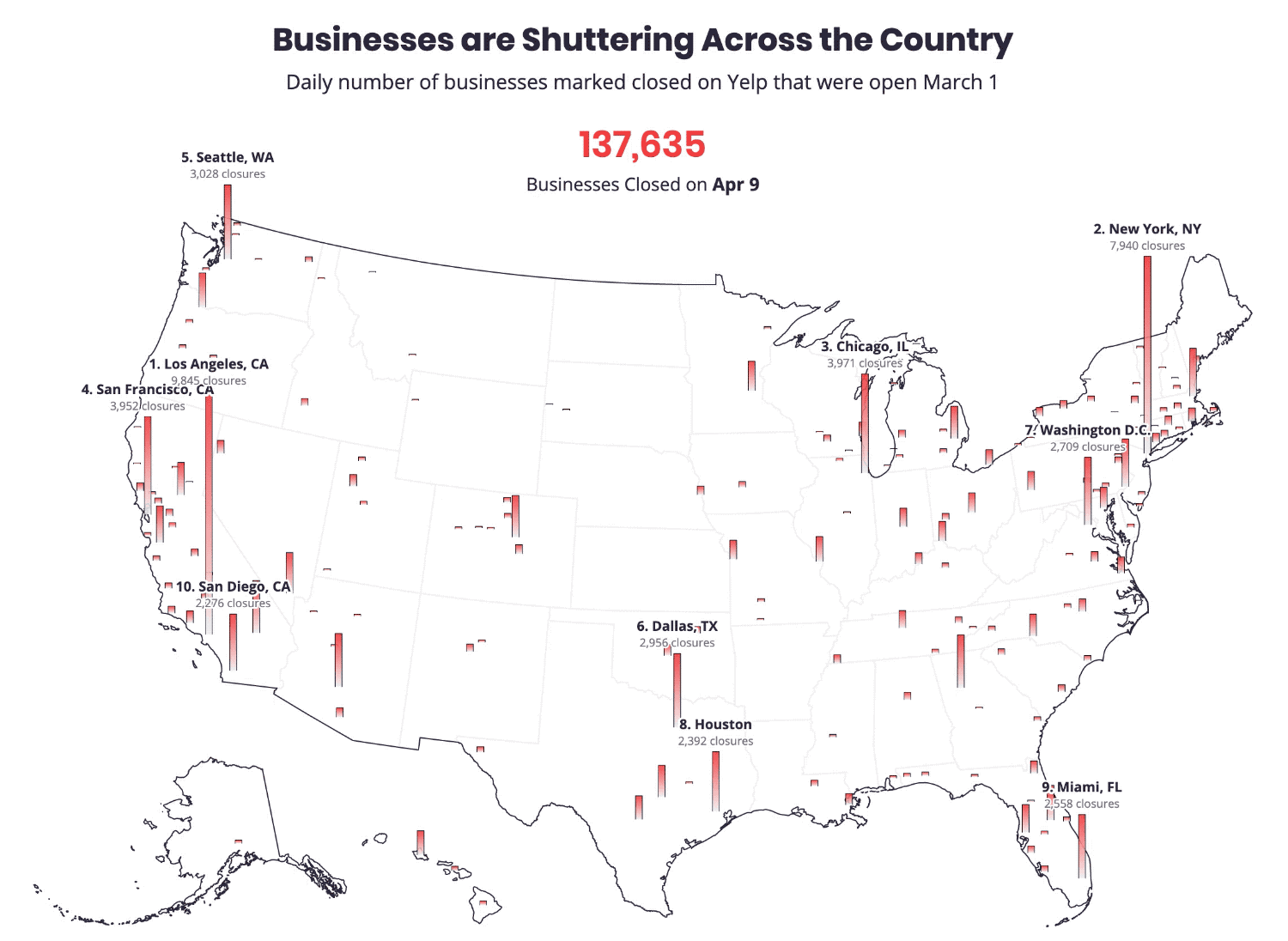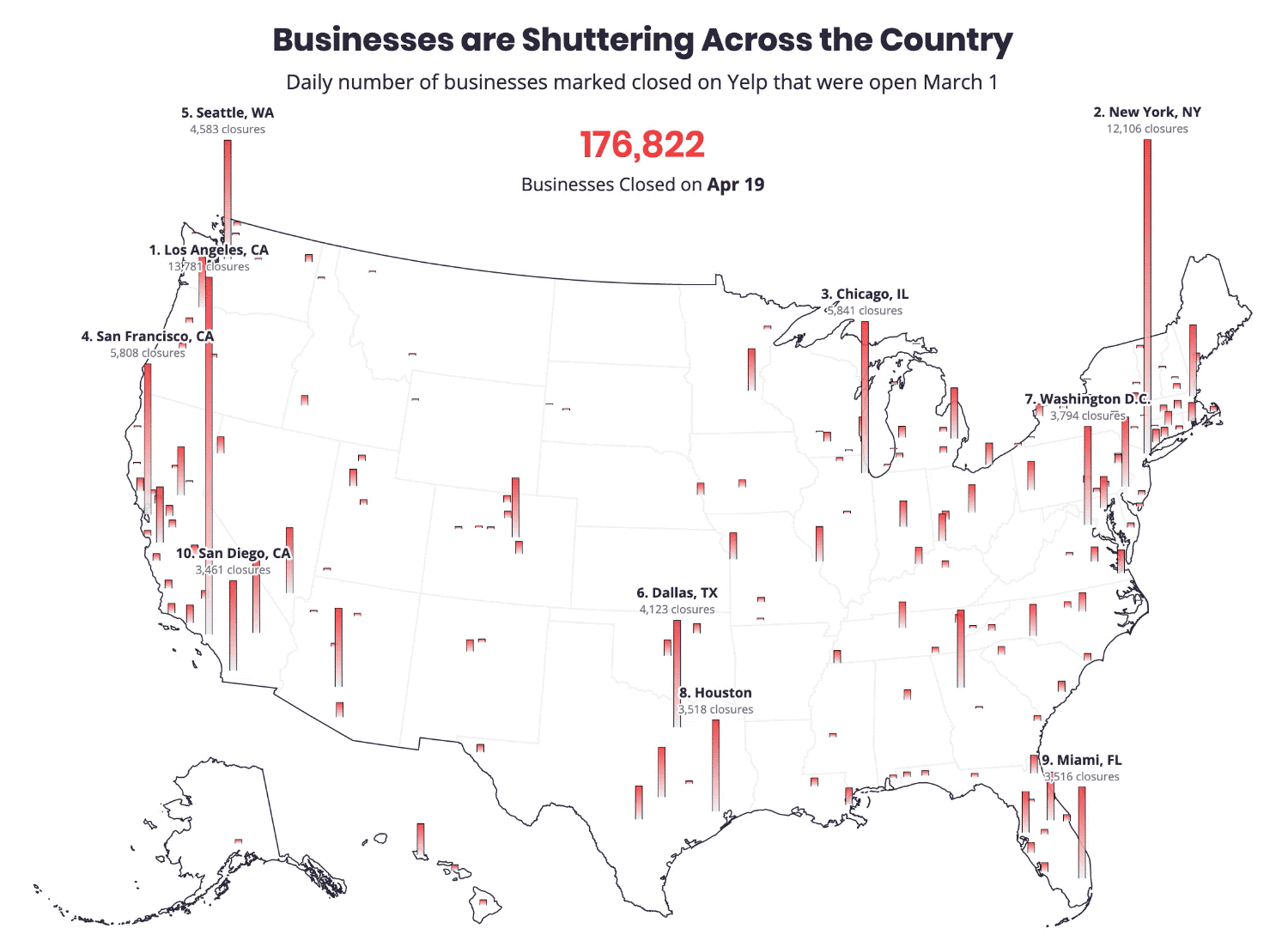
The biggest economic shock of the decade. Yelp likened COVID-19 and its fallout to “several hurricanes worth of local economic upheaval across the U.S.” Yelp explains the overall impact on local urban economies “amounted to four or more times the magnitude of the biggest prior economic shocks they’d experienced in the last decade, such as major hurricanes.” Among the findings in the report:
Interest and search activity declined by 50%. Following the stay-at-home orders, consumer interest “in all local businesses plummeted, by 50% or more in many categories, in a matter of a week or two.” Yelp explains that consumer behavior (e.g., search) often shifted immediately before and anticipated the government’s lockdown orders. Comparing economic impact of natural disasters and COVID 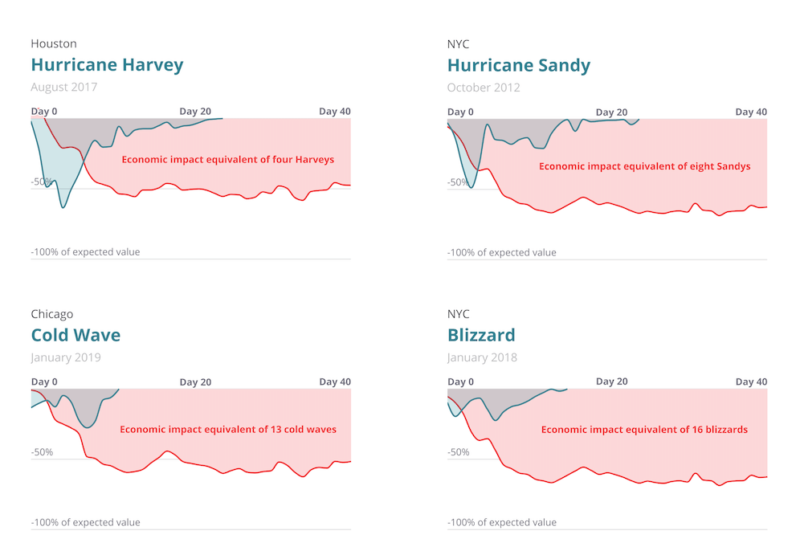
The graphic above compares COVID-19’s local economic impact (according to Yelp metrics) to recent natural disasters. COVID-19 is both larger and much more sustained — and it isn’t over yet. Reviews reflect consumer support, mention virus. From a consumer-demand perspective the hardest-hit categories on Yelp were bars and nightlife, salons, hotels and travel companies, and restaurants. However, Yelp also points to other categories and examples of SMB resilience, creativity and even increased demand in certain categories. Unlike Google, Yelp didn’t pause reviews. It explains that reviews often explicitly discuss “the health measures taken by establishments.” Yelp also says, “roughly one in six reviewers each day mentioned [the pandemic] by one of its names, a staggeringly high rate seen for few other types of phrases in our reviews.” Why we should care. Google hasn’t issued a comparable report but if it did the numbers would be significantly amplified I suspect. Indeed, an early April survey of more than 200,000 SMBs across North America found that 90% have been negatively impacted by COVID-19. And most SMBs have only about a month’s worth of cash reserves according to customer account data from JPMorgan Chase. As cities and towns open back up over the next two months, we’ll see how many SMBs return and how many are lost. Let’s hope SMB closures are more temporary than permanent, because significant failure rates will send a massive shock through the digital marketing ecosystem. The post Destructive impact of coronavirus on SMBs greater than an ‘economic hurricane’ appeared first on Search Engine Land. via Search Engine Land https://ift.tt/3aLI1px The post SEL 20200428 appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2zFqEKh 
More than half of businesses around the globe struggle to deliver on customer expectations for digital experiences. As a result, customers often look elsewhere and reward those companies that provide engaging digital experiences with their loyalty. Join us for this webinar to learn more about:
Register today for “Delivering Compelling Experiences to Modern Users,” presented by Progress. The post Deliver compelling digital experiences to modern users appeared first on Search Engine Land. via Search Engine Land https://ift.tt/2yQ3sbs Cookie-based experiments are now available on Microsoft Advertising, the company announced Monday. If this option is selected, customers will only be shown ads from either your experiment or your original campaign when they search. 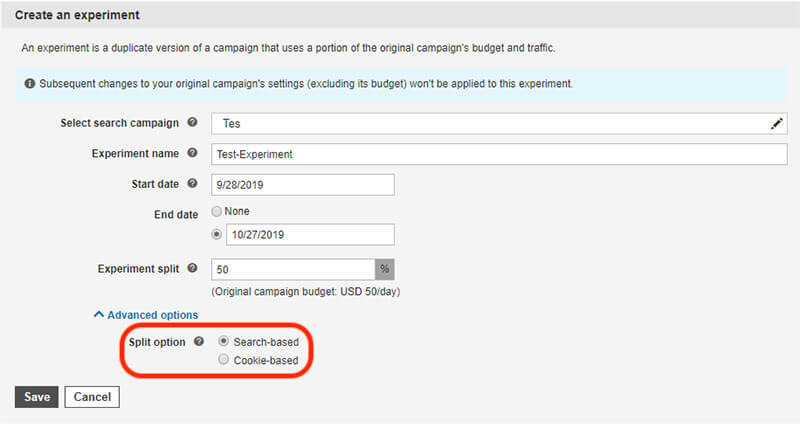
Why we careMicrosoft Advertising experiments enable you to create a duplicate of a campaign and test (on a segment of its traffic) whether an update works better for your business. The new cookie-based experimenting option ensures that once a customer is shown one version of your ad, they will continue to be presented with the same version. This facilitates more accurate testing of creative and ad copy as a customer is only responding to either the original campaign or the experiment. More on the announcement
The post Microsoft Advertising adds cookie-based experiment option appeared first on Search Engine Land. via Search Engine Land https://ift.tt/3aM3O0a The post SEL 20200427 appeared first on Search Engine Land. via Search Engine Land https://ift.tt/359xvqQ Google has updated many of the reports within Google Search Console to “cover a smaller number of pages, in order to provide better performance in Search Console,” Google wrote. The reports impacted include AMP, Mobile Usability, Speed, all rich result reports. What changed? Google said that in order to provide a quicker and more responsive Google Search Console experience, some of the reports are now reporting on a smaller number of pages. Specifically, Google is looking at fewer of your pages for generating the AMP, Mobile Usability, Speed, all rich result reports. This change happened on April 12, 2020. How are you impacted? Google said this is only a reporting change and that your search results are not impacted by this change. Google wrote “Because of this, you might see a decrease in the number of items and pages tracked in these reports. This change does not affect Search results, only the data reporting in Search Console.” Why we care. If you notice changes in the AMP, Mobile Usability, Speed, all rich result reports within Google Search Console, this may be why. It is important to understand this change may have nothing to do with any changes you made to your site. This is an internal Google reporting change and thus, if you use these reports – you need to notate the change in your reporting. The post Google Search Console reports may have changed appeared first on Search Engine Land. via Search Engine Land https://ift.tt/3cQ9sQm |
Archives
April 2024
Categories
|
