INTERNET MARKETING SUCCESS

Google accuses Bing of copying its search resultsIn 2011, the headline Google: Bing Is Cheating, Copying Our Search Results appeared first on Search Engine Land. As Danny Sullivan reported: “Google has run a sting operation that it says proves Bing has been watching what people search for on Google, the sites they select from Google’s results, then uses that information to improve Bing’s own search listings.” The story actually began in May 2010, when Google noticed that Bing was returning the same sites as Google when someone would enter unusual misspellings. By October 2010, the results for Google and Bing had a much greater overlap than in previous months. Ultimately, Google created a honeypot page to show up at the top of 100 “synthetic” searches (queries that few people, if anyone, would ever enter into Google). This story got picked up by dozens of media outlets as both companies got into a public war of words and blog posts. Google called Bing’s search results a “cheap imitation.” Meanwhile, Bing called the sting operation a “spy-novelesque stunt” and defended their monitoring of consumer activity to influence Bing’s search results. And all this happened on the same day as Bing’s Future of Search Event, where the Google-Bing dispute raged on in person. Oh what a day. Also on this dayAuto-tagging added to Google Merchant Center free listings2022: Tagging added URL parameters to your tracking URLs for better analytics and measurements. Microsoft rolls out portfolio bid strategies and automated integration with Google Tag Manager2022: The portfolio feature automatically adjusted bidding across multiple campaigns to balance under- and over-performing campaigns that shared the same bidding strategy. Google Search launches about this result feature2021: The feature helped searchers learn more about the search result or search feature they were interested in clicking on. Google adds Black-owned business label to product results2021: The label read “identifies as Black-owned” and showed in the product listing results within Google Shopping. Marketers say COVID vaccines create hope for quick return of in-person events2021: Marketers were seeing an end to conditions that have made business travel to training seminars, conferences and trade shows unsafe. Video: Dawn Beobide on Google confirmed vs unconfirmed algorithm updates2021: In this installment of Barry Schwartz’s vlog series, he also chatted with Beobide about the page experience update. Bing Ads rolls out multiuser access with single sign-on2018: Multi-User Access allowed users to have one email and password to access all of the Bing Ads accounts they manage. Restaurant owners can now edit menu listings in Google My Business2018: This made it possible to create a structured restaurant menu for display in mobile search listings directly in Google My Business. Google Assistant adds new media capabilities ahead of HomePod release2018: You could now wake up to a favorite playlist and use voice to pick up where you left off with Netflix shows. Google wins ‘right to be forgotten’ case in Japanese high court2017: Japan’s high court ruled that search results are a form of speech entitled to protection. Google’s Fake Locksmith Problem Once Again Hits The New York Times2016: Companies, often not based in the local area, set up fake locations within Google Maps to trick the algorithm into thinking they were locally based. Valentine’s Day Searches Start Now: When They’ll Peak Depends On The Category2016: Data from Bing provided key trends on Valentine’s Day-related searches — including gifts, candy, flowers, restaurants and jewelry — and ad performance. Google Search iOS App Adds “I’m Feeling Curious” To 3-D Touch2016: Hard pressing on the app brought up a menu for the “I’m Feeling Curious” button. Google Expanding Candidate Cards, Will Also Offer Primary Voting Reminders2016: In search and Google Now, users were able to get a combination of candidate-generated content and third-party content about the primaries and the election. Where Yahoo Might Again Compete In Search: Mobile2014: With the right content and user experience, Yahoo could have generated new “search” usage and ad revenue from mobile. Google Settles With France: No ‘Link Tax,’ But €60 Million Media Fund2013: The settlement ended several months of debate over France’s plan to charge Google for linking to French news content. Google Submits Formal European Antitrust Settlement Proposal2013: The proposal was required to address four “areas of concern” – “search bias” and “diversion of traffic”; improper use of third-party content and reviews by Google; third-party publisher exclusivity agreements; and portability of ad campaigns to other search platforms. Microsoft Sued By Company That Won Patent Lawsuit Against Google In 20122013: The two patents (originally issued in the early 1990s and owned by Lycos, which later sold them) pertained to the ranking and placement of ads in search results. The Lead Up To the Super Bowl: How Are We Searching?2013: Answer: On multiple devices. For information on the football teams, recipes and snacks. Search In Pics: The Google Business Card Collection, Silver Android Statue & Golden Gate Bridge Pin2013: The latest images showing what people eat at the search engine companies, how they play, who they meet, where they speak, what toys they have and more. French Court Fines Google $660,000 Because Google Maps Is Free2012: Google remained “convinced that a free high-quality mapping tool is beneficial for both Internet users and websites.” Google Pledges Crack Down on Unscrupulous AdWords Resellers2011: Under the terms, agencies had to provide their clients with metrics on costs, clicks and impressions on AdWords at least monthly, if not more often. Blekko Bans Content Farms From Its Index2011: Blekko decided to ban the top 20 spam sites from its index entirely, including ehow.com. Speculation, Intrigue Surround Google’s Delayed Cloud-Tunes Music Service2011: Licensing issues had delayed the service, despite Google offering boatloads of cash to music labels. Google Finally Adds Check-Ins To Latitude, With A Couple Twists2011: Latitude could send reminders to check-in at locations when you arrive, supported automated check-ins at places and automatically checked you out when you left a location. Google New Local Ad Category Invades The “7 Pack”2010: The local business ad (“enhanced listings“) allowed a business to stand out with an “enhanced” presence on the map or in the map-related listings on the SERP. The Latest On Google News Sitemaps2010: News publishers had through April 2010 to modify their news sitemap to accommodate the new protocol. Report: Google To Bring More “Transparency” To AdSense Revenue Sharing2010: Google sales boss Nikesh Arora reportedly said that Google would consider giving more transparency about revenue splits in AdSense. AP & Google Reach A Deal – Sort Of2010: Google and the Associated Press reached an agreement allowing Google to continue using AP content. But whether this is a long-term agreement was unclear. SEOmoz Leaves The Consulting Business To Focus On Software2010: The SEO agency had recently launched Open Site Explorer and offered a variety of SEO tools. Can Google Kill Microsoft’s Internet Explorer 6?2010: Google announced they would be discontinuing their support for “very old browsers.” US Appeals Court Allows Google Street View Trespass Lawsuit To Continue2010: The Boring couple had first sued Google in early 2008 for taking pictures of their suburban Pennsylvania home, which was on a clearly marked private road. 2000 In Review: AdWords Launches; Yahoo Partners With Google; GoTo Syndicates2010: Major events from the year 2000 in consumer search. Can Searchers Find The Superbowl?2009: Search engines and websites still had lots of room to improve in order to connect with searchers. Scoring The Superbowl Ads & Search: Do Broadcast Marketers Get Online Acquisition?2009: It was the year of the microsite. Microsoft Makes $45 Billion Bid To Buy Yahoo2008: Microsoft was ready to bid $31 per share to Yahoo’s board of directors to purchase the company, a deal potentially worth $45 billion. (Yahoo ultimately rejected this bid – and it wouldn’t be the last time.) More coverage of the bid:
Mine The Web’s Socially-Tagged Links: Google Social Graph API Launched2008: The API allowed developers to discover socially-labeled links on pages and generate connections between them. “Open Network” A Reality, C Block Of 700MHz Spectrum Hits $4.6 Billion “Reserve Price”2008: Effectively, the rules required that “any legal consumer device” must be allowed to access the C Block broadband network. Up Close With Yahoo’s New Delete URL Feature2007: Pages would continue to be crawled, they just wouldn’t get indexed. Google News Engine Bugging Out2007: It was returning 500 errors, graphics weren’t loading and searches weren’t working. National Pork Board Goes After Breastfeeding Search Marketer2007: The National Pork Board thought one of her project’s T-shirts violated their trademark on the phrase “The Other White Meat.” Google Fensi: Google’s Asian Social Networking Site?2007: Was it a social network? A game? Or service. We may never know. Marchex Launches Review Aggregation Feature ‘Open View’2007: Open View aggregated user and expert reviews and generates a dynamic summary in more or less a single paragraph. Google To Kick Off X Prize’s Next Fundraising Campaign2007: X Prize’s mission was to “create radical breakthroughs for the benefit of humanity.” Aussies Turn Out For Battle Of Sydney; Google Gets Shot Down2007: Google’s flyover to snap imagery of the Sydney landscape and residents didn’t go as planned. From Search Marketing Expo (SMX)Past contributions from Search Engine Land’s Subject Matter Experts (SMEs)These columns are a snapshot in time and have not been updated since publishing, unless noted. Opinions expressed in these articles are those of the author and not necessarily Search Engine Land.
< January 31 | Search Marketing History | February 2 > The post This day in search marketing history: February 1 appeared first on Search Engine Land. via Search Engine Land https://ift.tt/rOUSovB
0 Comments

With the inevitable demise of cookies, marketers are scrambling for ways to deliver personalized experiences with user consent, all without compromising convenience or security. Today, many are turning to the login box as a critical first step in executing an effective first-party data strategy. It’s no longer just a security requirement – it’s now the doorway into their brand’s digital user experience. Join Salman Ladha, senior product marketing manager from Okta, as he shares techniques that marketing and digital teams can use to remove friction from their login experience – leading to improved acquisition, retention, and increased revenues. Register today for “Kickstart Your First-Party Data Strategy,” presented by Okta. Click here to view more Search Engine Land webinars. The post Webinar: Kickstart your first-party data strategy appeared first on Search Engine Land. via Search Engine Land https://ift.tt/JoLwRXg OpenAI, the creator of ChatGPT, today released an AI Text Classifier that might be able to help you determine whether the text you’re reading was written by AI or a human. But there’s a but. OpenAI notes it’s “impossible to reliably detect all AI-written text” and it has “not thoroughly assessed the effectiveness of the classifier in detecting content written in collaboration with human authors.” Why we care. There are already a variety of AI content detectors. If these tools are able to do a fairly effective job of identifying AI-generated text, it’s safe to assume search engines can. Think: Google’s helpful content system. Also, if you are publishing content, it may be smart of you to run any content submitted by your agency or freelance writers through these tools. We’re entering a new era – and you don’t want to publish anything that could potentially get your site flagged as publishing automatically generated content, which is against Google’s guidelines. We have already started using tools like this for all contributed content here at Search Engine Land. What is the AI Text Classifier? OpenAI calls its new tool a “fine-tuned GPT model that predicts how likely it is that a piece of text was generated by AI from a variety of sources, such as ChatGPT.” It has some limitations – most notably the results may be inaccurate. OpenAI primarily trained the tool on English content written by adults so it’s entirely likely there will be false positives. Also, as OpenAI pointed out, it’s easy to edit AI-generated text to pass as human-generated. As noted in its FAQ section:
The results of the classifier. After you paste your text into tool (Open AI says you need a minimum of 1,000 characters, which is roughly 150-250 words) the AI Text Classifier will evaluate whether the text was generated using AI. You will see one of five labels:
Here were the results after I pasted in the text of this article you’re reading (human written, I swear): 
And thankfully, the classifier thought it was “very unlikely” that this article was AI-generated. Try out the tool for yourself. OpenAI’s AI Text Classifier. It’s free. More coverage. You can read OpenAI’s announcement here: New AI classifier for indicating AI-written text. You can see more coverage on Techmeme. The post OpenAI launches new tool to detect AI-generated text appeared first on Search Engine Land. via Search Engine Land https://ift.tt/bYQBzpZ Twitter has just announced the end of CoTweets. They put out a statement in their Help Center that the new feature, which started in July, will be sunset by the end of the day on January 31, 2023. 
A CoTweet is a tweet that has two authors’ profile pictures and user names. A CoTweet appears on both users’ profiles and is shown to all of their followers. Twitter warned us about this. When the CoTweet experiment was announced, it was also made known that this may not be a permanent feature and that it could go away. Why we care. This feature was a short-lived experiment with the potential for brands and individuals to reach wider audiences. Clearly, Twitter deemed the feature a loser under Elon Musk after not meeting expectations. The post Twitter announces the end of CoTweets appeared first on Search Engine Land. via Search Engine Land https://ift.tt/thcN1ar You can now customize SEO titles and descriptions for any LinkedIn articles you will publish or have already published. Why we care. Whether you’re using LinkedIn to grow an audience for yourself, your company or your clients, you want to take advantage of every opportunity you can to increase your search visibility and discoverability. This is super basic SEO – and it’s likely you were probably already creating your headlines with search in mind already. But it is a nice option to let you optimize your content specifically for search. How it works. Click on Write article. Under the Publishing menu in the article navigation pulldown menu, click on Settings. Here’s you’ll see two fields:
What it looks like. Here’s a screenshot: 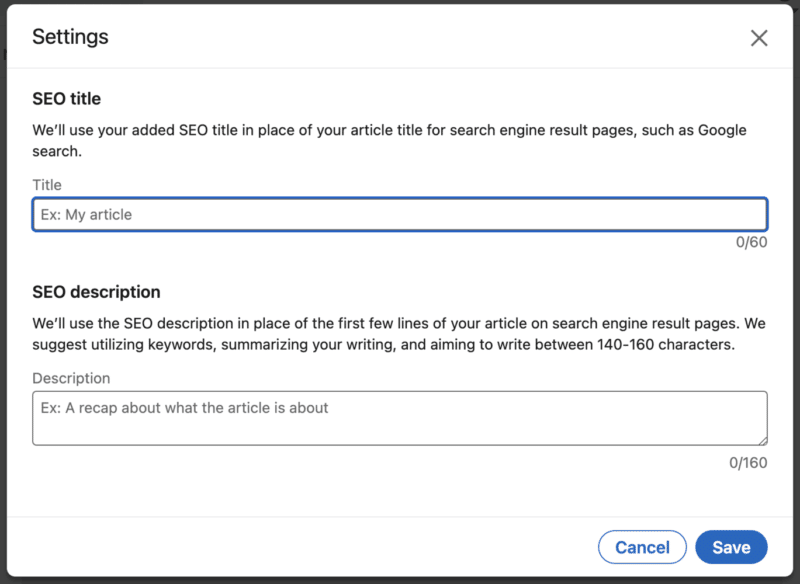
Newsletters gain visibility in search. LinkedIn is also increasing the prominence of Newsletters in search results. Now if a LinkedIn creator offers a newsletter, it will appear under the author’s name, along with a Subscribe button. Here’s an example: 
Scheduled articles coming soon. LinkedIn also announced the article and newsletter authors will be able to schedule articles. These will work in the same way as scheduled posts. And more. You can see all this news and more in the latest Building LinkedIn newsletter: Creators’ Edition: newsletters enhancements, SEO, analytics & more + Inspiring conversations about building character, finding your next play, AR & AI The post LinkedIn now lets you add an SEO title and description appeared first on Search Engine Land. via Search Engine Land https://ift.tt/TvW7wlX Internal linking is a crucial aspect of any website, but it is especially important for ecommerce websites. Internal linking helps improve the navigation and user experience for your website visitors and can also help improve your website’s search engine optimization (SEO). This article will discuss the best practices for internally linking pages on ecommerce websites. To help illustrate these opportunities, I’ll use some of my favorite examples of ecommerce SEO done well – the portfolio of Williams Sonoma brands. (Disclaimer: I have no affiliation and have never worked on any of these sites.) But first, let’s lay the groundwork for why these tactics are so important. What is internal linking?Internal linking refers to linking one webpage to another on the same website domain. When a user clicks on an internal link, they will be taken to a different page on your website. These links can be words, phrases, or images. Internal linking is important because it helps people find the information they are looking for on your website and helps them move from one page to another. It also helps search engines understand the structure and hierarchy of your website, making it easier to find in search results. What internal linking is notInternal linking is not the same as external linking. External linking is when you put links on your website that take users to other websites. This can help them find relevant information from other sources. Using both types of linking is essential, but they have different purposes. Why is internal linking important for ecommerce websites?Internal linking is an important aspect of search engine optimization (SEO) for all websites, especially ecommerce. While there are probably many more reasons than I’ve listed below, these are the four primary reasons that are always top of mind when working on an ecommerce website with tens of thousands, if not millions, of pages.
It helps improve the visibility and ranking of a website on search engine results pages (SERPs) and improves the user experience by allowing visitors to navigate the website easily. But, before we get into general best practices, as noted in the items above, it is essential to note the difference between navigational internal linking and in-content internal linking. In-content vs. navigation internal linking: What’s the difference?In-content internal linking includes links within the content of a page (typically a blog post), while navigation internal linking is when you have links in your website's navigation menu. For example, if you are writing a blog post about men's shoes, you may want to link to a page about sneakers. This would help users find additional information related to the current page's content. In contrast, navigation internal linking helps people find the main pages on your website and navigate your website more easily. With that explanation out of the way, here are 9 best practices for internally linking pages on ecommerce websites, broken down by in-content or navigational. Navigation internal linking best practicesLet’s start with some of the basics for a solid ecommerce website. 1. Sitewide navigation menuThe organization and utilization of your primary navigation are table stakes for a robust internal linking strategy. When a page is linked from the sitewide menu, it essentially means that it is linked from every page on the site, which can signal to Google that the page is essential. However, it's necessary to be mindful of not overcrowding your menu. Across the Williams Sonoma portfolio of sites, the main navigation is a master class of effective internal linking strategy. I’ll use the below example from West Elm’s Kids section to illustrate. 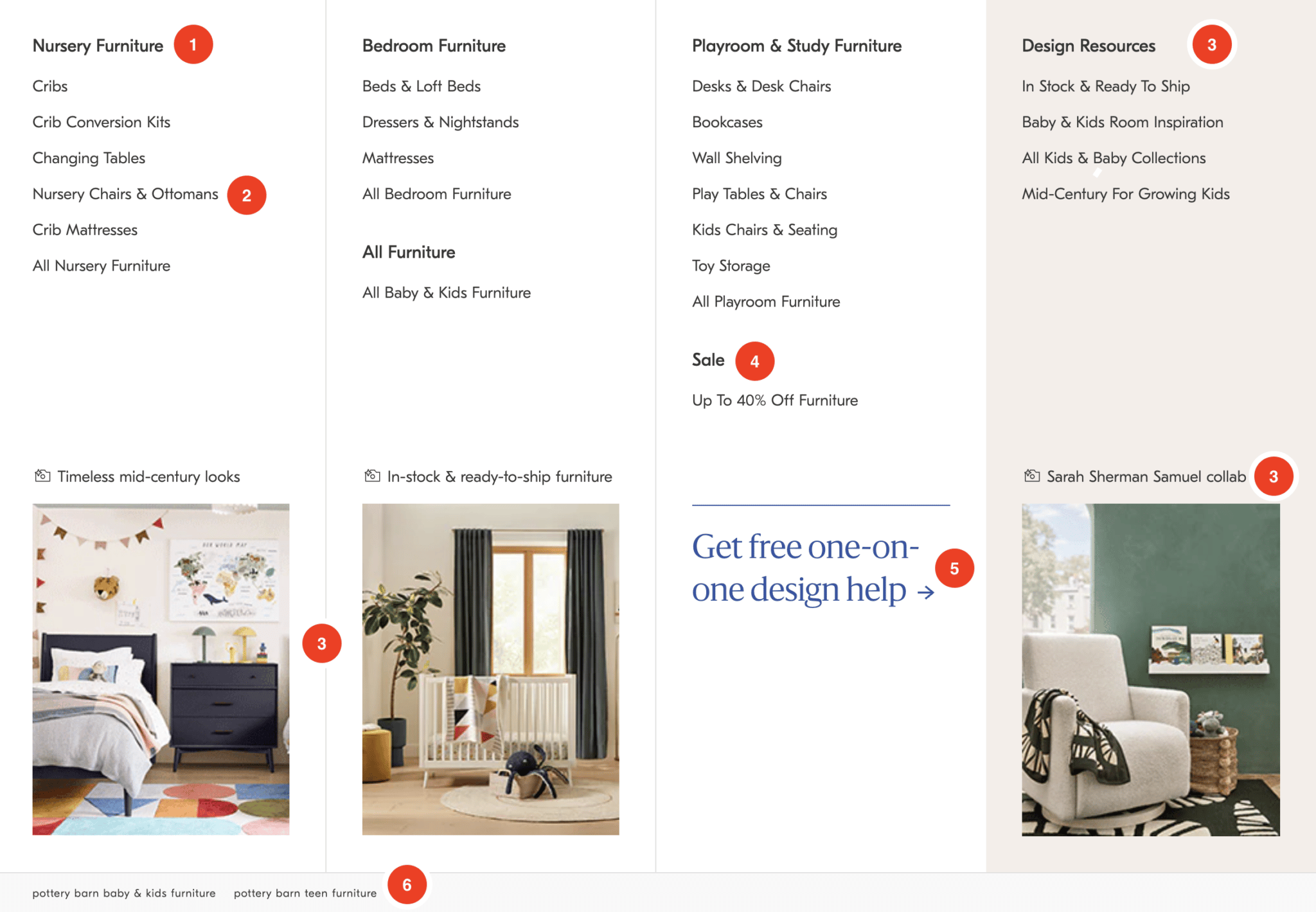
1 and 2 – Category / Sub-Category Linking: West Elm links to crucial category pages from the sitewide menu, boosting these pages' internal authority. The sub-category links assist in providing Google with a better understanding of the organization of the website and the semantic relationships between them. 3 – Focusing on the user journey: Having dealt with this myself, I know design paralysis is a big blocker to purchasing furniture. With the Design Resources section, West Elm not only provides search engines an entry to all products in the category (All Kids & Baby Collections) but also answers common blockers to purchase (inspiration, in stock, etc.). Ross Hudgens summarizes the additional benefits of including this content more eloquently than I could:
4 – Internally link to support business priorities: The critical thing to note about this example is the internal link doesn’t just say “Sale.” It is a specific sale (“Up To 40% Off Furniture”) aligned with the category. As you navigate each sub-menu, you’ll find that the sale references align with the primary category. Great use of deep linking, even within the sale section. 5 – Internal link to support secondary KPIs: In an age where first-party data collection must be a priority, West Elm provides a clear CTA driving users into their design center to schedule an appointment. While I cannot validate this, I would expect the data collected to be used to fuel additional marketing efforts. Ultimately, if someone chose to utilize these services, I expect these average order sizes to be much larger (I know it was for me), which is also likely why they can offer these design services at no cost. 6 – Portfolio-wide internal linking strategy: I’ve worked on many ecommerce sites that were part of portfolio companies. The typical approach is to add a bunch of footer links to the portfolio domains and call it a day. This is the first time I have seen such a focused effort on utilizing an internal linking structure to elevate all domains in a portfolio. The important element to note here is that even the cross-domain internal link is highly relevant (e.g., West Elm Kids Furniture → Pottery Barn Baby & Kids Furniture). Kudos to whoever sold this enterprise SEO strategy! 2. Sitewide secondary navigation menuThe Williams Sonoma site portfolio uses a mix of global navigation menus. I’ll focus on the two in the screenshot below. 
At the top, again, we see a list of external links to ecommerce sites in the portfolio. (Gap also does this well.) Directly below the logo, Mark & Graham utilizes a row of “quick links” that are updated to support seasonal efforts, promotions and sales, new product categories, and other deep links to category pages that otherwise might not have a home in the fixed navigation menu (i.e., Occasions, Interests, etc.) This is an excellent example of secondary navigation that adds value to the user (and search engines) beyond just Find a Store, Shopping Cart, etc. 3. HTML breadcrumb navigationHTML breadcrumbs are typically displayed at the top of the category and product pages. They include a series of links that show the path a user has taken to reach the current page. There are a handful of benefits of implementing breadcrumbs: They help users understand where they are on the website and make navigating to previous pages easy.
A perfect illustration of this is Williams Sonoma’s utilization of breadcrumbs to build natural internal links to essential category pages based on my navigational path to the same product: 


4. HTML sitemapAn HTML sitemap is a page that lists all pages on your website and provides links to these pages. For example, you might include a sitemap on your website that lists all of the pages on your website and provides links to these pages, or you could use internal linking to highlight the most critical pages on your website. 
Creating a well-structured HTML sitemap and linking to it from the footer, as Pottery Barn Kids has done, ensures that most site pages are only a few clicks away, which aids in both user accessibility and SEO. 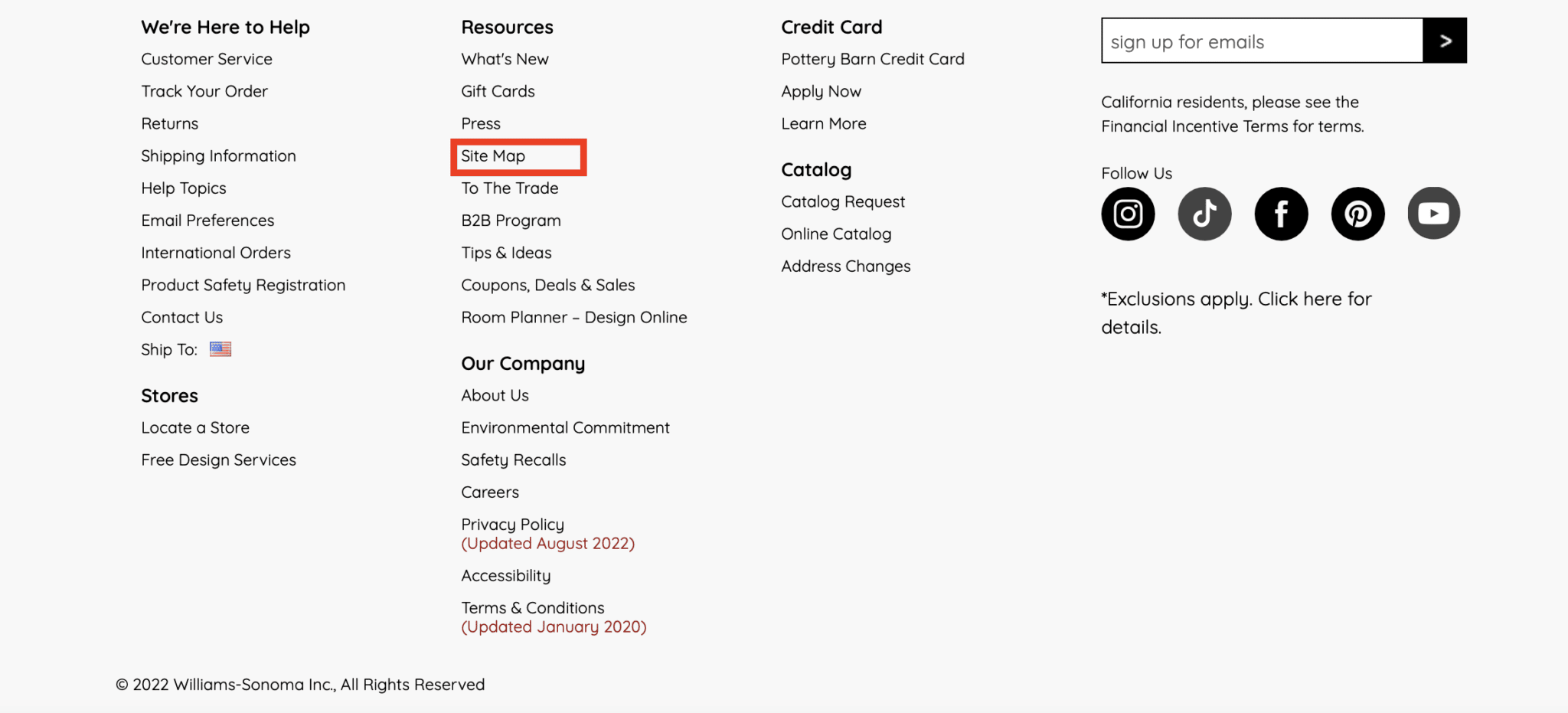
Since search engines crawl sites in a sequential manner and follow contextual cues, it is beneficial to have a single page that links to the site’s primary and secondary pages. This can be helpful for users looking for specific pages on your website and help search engines discover and crawl all of the pages on your website. Once created, it is essential to maintain an updated HTML sitemap on the site to ensure users and search engines can reach any page via minimal navigation. In-content internal linking best practicesEcommerce sites are notorious for lacking content – especially across category and sub-category pages. As a result, it could be argued some of these examples are "navigational" in nature. However, I might argue these implementations are less ‘standard’ for navigational purposes and typically buried at the bottom of the page (where content is generally added for category pages). 5. Supporting category page contentThere are many ways to build in supporting content on category pages – that could be a separate article. In the example below, West Elm adds a few supporting paragraphs at the bottom of their category pages with additional heading tags and content that adds value to the user experience. Within that content, they naturally include links to other category and sub-category pages, individual product pages, and even educational/blog content where it makes sense. 
6. Internal linking modulesAbove the supporting page content, Pottery Barn, Mark & Graham, and West Elm utilize a row of Related Searches (read more about internal link modules here). 
Pottery Barn Kids utilizes this same row directly above the footer. 
In all cases, these text links take the form of long-tailed keyword-rich internal links to sub-categories and product detail pages (PDPs). As you can see from the example above, this provides opportunities to build rich anchor text links to pages around color, texture, and even sizing – incredibly valuable for those long-tailed but highly-qualified searches. 7. Related products/browsingEcommerce SEO 101 requires a related products widget of some sort. This can help users discover additional products they may be interested in and is one of the foundational tactics for internal link building. However, what was traditionally reserved for the product detail page, has expanded to category pages, and even the “types” of related products have grown exponentially. For example, Williams Sonoma uses the standard “Related Products,” while Pottery Barn uses a “Top Picks for You” widget on their category pages. 
On product detail pages, this implementation expands to a wide variety of implementations and names, typically with multiple rows per page in a carousel allowing for a more extensive list of internal links per page:
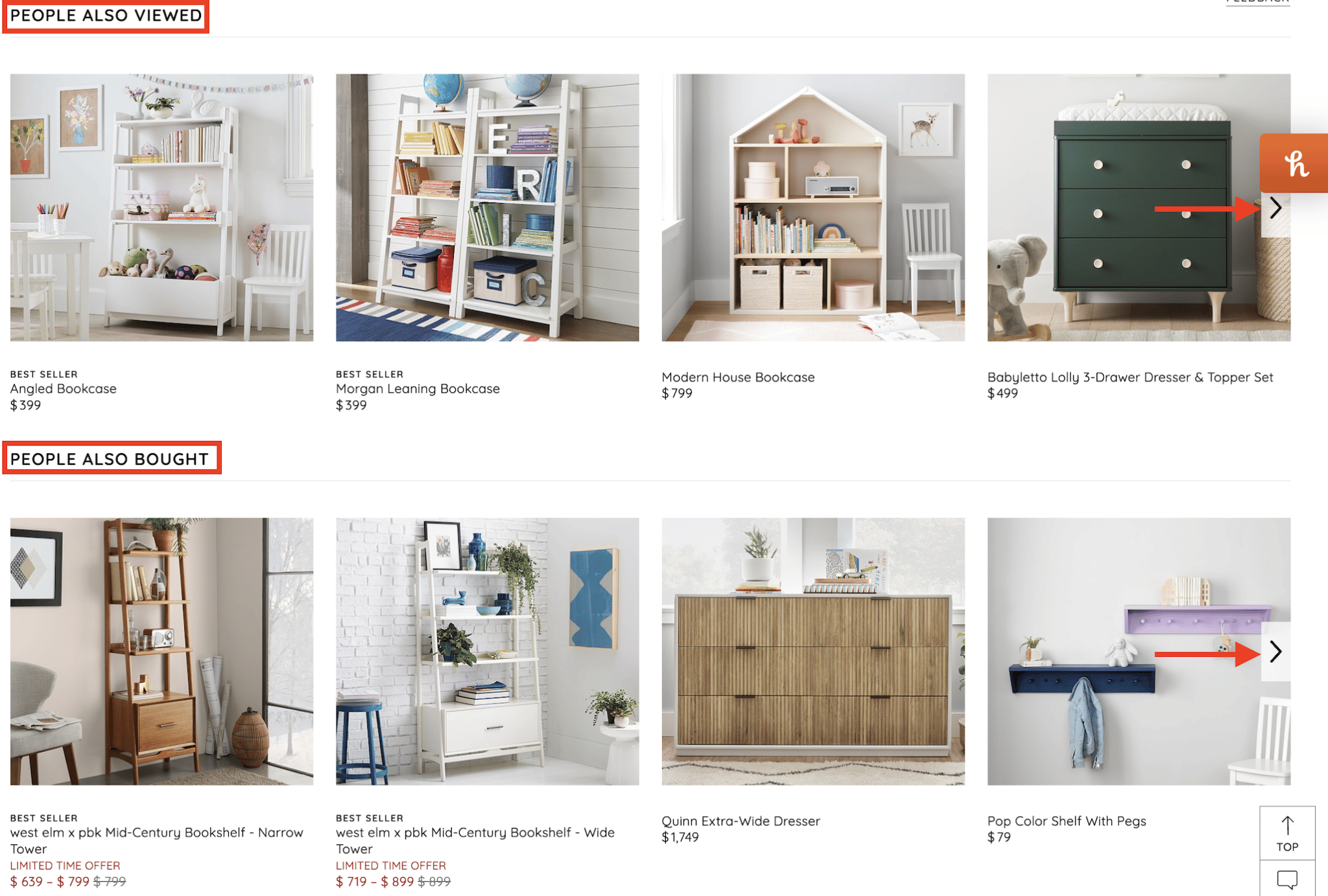
These links are invaluable for cross-selling, upselling, and flattening the overall website architecture. 8. Product attributesWhere breadcrumbs might not be possible, product attributes can fill the void. When both can be used, they are an effective complement for each other and can reference any/all attributes a product might have:
While this type of internal link is perhaps better showcased on another site (check out REI.com), I was able to find an example of this on West Elm: 
In this case, “Learn more” links to the collaboration page for Scout Regalia. I would argue that a better anchor text implementation could be done here. There are broader opportunities across the collective sites to take advantage of interlinking among collaborations and brand pages on product detail pages themselves. 9. User-generated content (UGC)UGC content can take on many forms:
It’s hard to find fault in Williams Sonoma’s SEO strategy. This, however, is one area where there might be a significant opportunity. 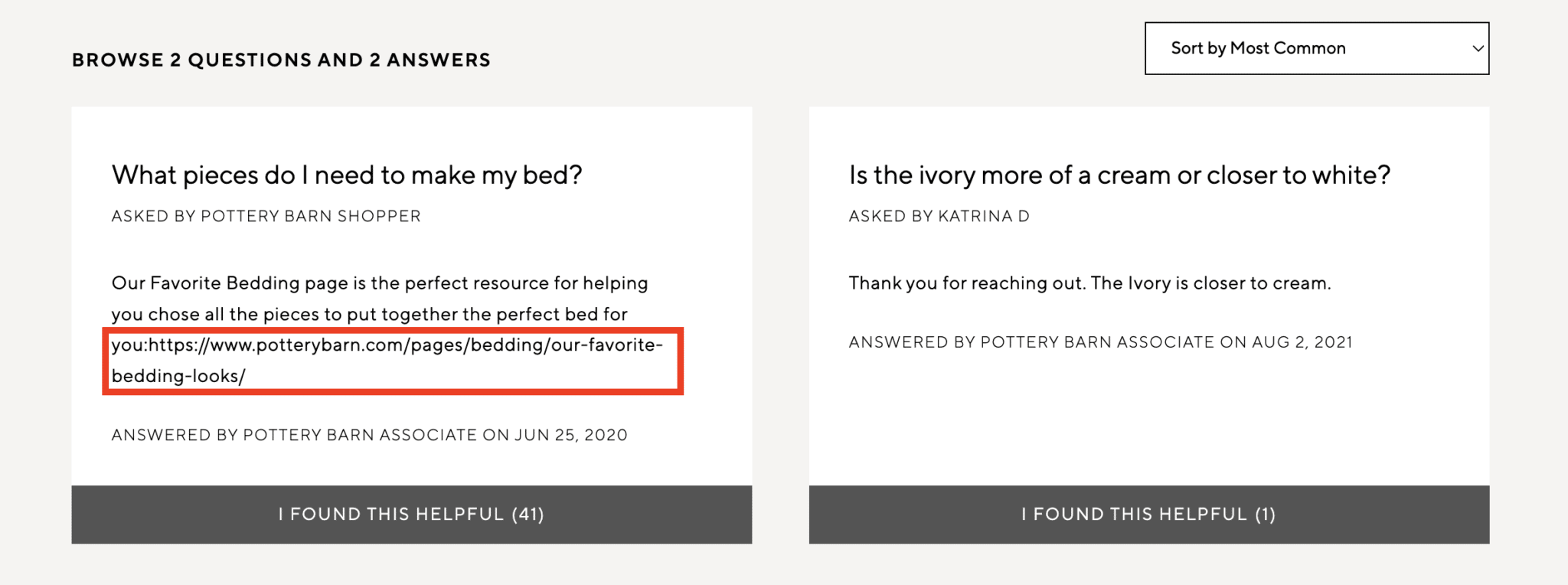
In the example above, a Pottery Barn associate left a response to a comment with a naked URL. However, the link is not clickable. Generally, the Q&A section across the domains offers many opportunities for internal linking automation. What are general internal linking best practices?Now that you have a roundup of the why and where to incorporate internal links, you might wonder “what to do” and “how to do it.” A myriad of articles outlines these internal linking best practices very well, including Moz, Semrush, and, of course, Google. I suggest you dive into the links above for a more detailed breakdown. In my opinion, the five most crucial internal linking best practices to follow, in no particular order, are below:
How do I implement internal linking on my ecommerce site?Much of this may require some grunt work and a partnership with your development team to implement these strategies effectively. The implementation with the most bang for your buck (and potentially the highest level of effort) is internal linking modules. I linked it above, but I highly recommend reading this article from Holly Miller Anderson for more details. Alternatively, auditing your existing internal links to determine which pages could benefit from increased internal linking is always a great place to start. Paul Shapiro defines this process as determining “internal PageRank,” which is an intelligent way of thinking about it. No matter how you define it, the outcome of this exercise will no doubt provide valuable insights to get started. Maximizing internal linking for ecommerceInternal linking is an essential aspect of any ecommerce website. By following the best practices discussed in this article, you can ensure that your website is easy to navigate for users and is optimized for search engines. The post Internal linking for ecommerce: The ultimate guide appeared first on Search Engine Land. via Search Engine Land https://ift.tt/bPSYoR0 As Instagram and Facebook continue to lead the social platform arena, Meta remains a media channel where advertisers must stay visible and competitive in 2023. Much has changed over the past year, with Meta releasing many new tools and features. Advertisers now have more resources to scale their campaigns faster than ever. Meta continues to dominate machine learning, launching new automated campaign types proven incredibly efficient. Advertisers have more options to control certain elements in campaigns. The media giant also improved the experience of working with influencers, a value-add to advertisers who seek to focus on their brand awareness budgets over direct response. With all the new updates in 2022, several best practices were uncovered through rigorous testing, many of which prove vital for any brand’s long-term Meta advertising strategy. Here are five recommendations to consider when running Facebook and Instagram advertising campaigns in 2023. 1. Leverage Advantage+ campaignsAdvantage+ campaigns is a new feature Meta released in 2022. I’ve always advocated for Meta’s machine learning because they have mastered it. Advantage+ campaigns are a great addition to app and shopping initiatives. Meta does the work for advertisers by finding the right audience and the right creative. We have succeeded across app install and shopping (dynamic product ads). To capitalize on Advantage+ campaigns, it’s essential to ensure you have a healthy amount of creative to get these running effectively. Meta recommends the creative assets they think will perform the best, but marketers can manually select the ones they desire. Experiment with your options and try a combination of ads known to perform well while also letting Meta choose ads. By testing and optimizing what works, you’ll likely see an improvement in your cost-per-acquisition running with Advantage+ campaigns. Keep your eye on these for 2023. 2. Work with influencersNot a new tactic, but Meta has recently put forth new playbooks and guides to help advertisers work with influencers. Influencers are a large part of B2C advertising budgets, and Meta has recognized that marketers want to leverage user-generated content on brand channels with paid media. The process isn’t perfect, but here are a few key best practices to make your strategy go as smoothly as possible.
Also, keep in mind that if you’re promoting Reels, advertisers can only add links to these if you create a dark post. If it’s important that you have a link, but you don’t want a dark post, Facebook recommends going with the “Story” placement. Advertisers working with influencers can additionally find success with the “Instagram Explore” placement, so it’s highly recommended to keep an eye on that one for 2023. We’ve seen our lowest CPMs and CPAs from Instagram’s new “Explore” placement and plan to increase spend here on future influencer initiatives. 3. Set up Meta’s Conversions APIYes, there are still many pain points and kinks to be worked out when setting up Meta’s Conversion API (CAPI). However, Meta has recently rolled out various setup methods to help more advertisers get up and running. While CAPI isn’t mandatory, it’s worth keeping in mind since it’s a deeper level of optimization. With the new setup methods, it also appears Meta is (hopefully) working to offer more integrations for advertisers to get set up faster without needing a full dev team. After successfully getting CAPI set up and launched, we delivered our lowest cost-per-acquisition of the year in Q4. Our CPA decreased by 34% in our first month and 70% in our second month while optimizing for conversions using CAPI. We were able to feed a deeper data point to Facebook’s algorithm. Stay on the lookout for more Meta updates regarding CAPI setup. This is one feature you don’t want to miss out on. 4. Use ‘open’ and ‘broad’ targetingAligning even more with Meta’s machine learning algorithm, “Open” or “Broad” targeting will continue to be king when scaling your campaigns. Meta’s algorithm can efficiently find the audience most likely interested in your ads and taking action when doing either of these two options:
Open and broad targeting feeds Meta the most audience data to allow it to make the best optimizations, which is the best way to make machine learning work for your advertising efforts. 5. Make the best of lead gen formsLong has been the theme of “less is more” regarding lead gen forms. This remains true in many cases. But if you’re struggling with the quality of leads, consider adding more questions to qualify the customer. We’ve seen this successful when needing to drive quality over quantity. Yes, your front-end cost per lead will likely increase. Still, we’ve found that the quality on the backend significantly improves and decreases the efficiency of qualified leads while driving increased revenue for businesses. It’s also recommended to test manual fill for first name, last name and/or email address if you’re struggling with the quality. There is a balance to be found when it comes to manual fill vs. autofill so you’ll likely want to test a few variations to find what works best for your business. Don’t have too many manual fill questions to avoid accidentally increasing the volume of abandoned forms. Consider additionally giving the consumer a short and sweet introduction on the form that details what they will get from filling out the form. This can be a snippet of a whitepaper or a few bullets about the company – whatever makes the most sense for your ad. Moreover, ensure your thank you page or the landing page you are driving the consumer to is engaging with helpful information and resources. This provides more education for the consumer to make decisions and can help build your retargeting audiences for nurture campaigns. Lastly, keep the creative for your lead gen forms scroll-stopping. You have seconds to grab someone’s attention in their feed and make them stop to open your form, so be bold! The takeawayAs Meta continues to evolve and unroll new features, one thing is certain – automation will become a core campaign tactic. With automation at the forefront, advertisers have more ability to test and learn at a faster pace than ever with tools like CAPI and Advantage+ campaigns. Furthermore, don’t hesitate to lean into open and broad targeting, where possible, to feed audience optimization. 2023 will be a big year for testing to see where advertisers can uncover additional efficiencies and remain competitive on Facebook and Instagram. The post Meta advertising: 5 best practices for 2023 appeared first on Search Engine Land. via Search Engine Land https://ift.tt/FVXsySb Google releases URL Inspection Tool APIIn 2022, Google released a new API under the Search Console APIs for the URL Inspection Tool. The new URL Inspection API let you programmatically access the data and reporting you’d get from the URL Inspection Tool but through software. Google’s URL Inspection Tool API had a limit of 2,000 queries per day and 600 queries per minute. Google provided some use cases for the API:
Within a week, several SEO professionals developed free new tools and shared scripts, and established SEO crawlers integrated this data with their own insights, as Aleyda Solis rounded up in 8 SEO tools to get Google Search Console URL Inspection API insights. Also on this dayGoogle Search Console error reporting for Breadcrumbs and HowTo structured data changed2022: This change may have resulted in seeing more or less errors in your Breadcrumbs and HowTo structured data Search Console enhancement and error reports. Recommendations roll out to Discovery campaigns2022: Google Ads also launched auto-applied recommendations for manager accounts and more recommendations for Video campaigns. Google Ads creates unified advertiser verification program2022: Google would combine its advertiser identity and business operations verification programs under a unified Advertiser verification program. Deepcrawl launches technical SEO app for Wix2022: Designed for small and mid-sized enterprises, the app automated weekly site crawls and detects issues ranging from broken pages to content that doesn’t meet best-practice guidelines for SEO. Pinterest rolls out AR ‘Try on’ feature for furniture items2022: The augmented reality feature, called “Try On for Home Decor,” let users see what furniture looked like in their home before buying. Meta descriptions and branding have the most influence on search clickthrough, survey finds2020: The majority of participants also agreed that rich results improved Google search. Microsoft: Search advertising revenue grew slower than expected last quarter2020: LinkedIn sessions grew faster than the previous three quarters, though revenue growth slowed slightly in the second quarter of its fiscal 2020. Bing lets webmasters submit 10,000 URLs per day through Webmaster Tools2019: Previously you were able to submit up to 10 URLs per day and maximum of 50 URLs per month. Bing increased these limits by 1000x and removed the monthly quota. Client in-housing, competition for talent top digital agency concerns2019: Marketing Land’s Digital Agency Survey found the sector was weathering digital transformation well, but the growth of data-driven marketing made it clear where they needed to hire. Quora adds search-like keyword targeting, Auction Insights for advertisers2019: Quora introduced three new metrics (Auctions Lost to Competition, Impression Share, Absolute Impression Share) to help advertisers understand how they performed in the ad auctions. Google’s Page Speed Update does not impact indexing2018: Indexing and ranking are two separate processes – and this specific algorithm had no impact on indexing. Bing Ads has a conversion tracking fix for Apple’s Intelligent Tracking Prevention2018: Advertisers had to enable auto-tagging of the Microsoft Click ID in their accounts to get consistent ad conversion tracking from Safari. Google EU shopping rivals complain antitrust remedies aren’t working2018: They demanded more changes, saying their problems have intensified rather than improved since the EC ruling in June 2017. Google mobile-friendly testing tool now has API access2017: Developers could now build their own tools around the mobile-friendly testing tool to see if pages are mobile-friendly. AdWords IF functions roll out for ad customization as Standard Text Ads sunset2017: IF functions arrived to let advertisers customize ads based on device and retargeting list membership. Google launches Ads Added by AdWords pilot: What we know so far2017: Ads based on existing ad and landing page content were added to ad groups by Google. New AdWords interface alpha is rolling out to more advertisers2017: It would roll out to even more AdWords accounts in the next few months. Majestic successfully prints the internet in 3D in outer space2017: The 3D printer worked in outer space, and the Majestic Landscape was printed at the International Space Station. Nadella Would Bring Search Cred To Microsoft CEO Role2014: For the prior three years Nadella had run Microsoft’s Server & Tools business. Before that he was in charge of Bing and online advertising. Bing Ads Editor Update Gives The Lowly “Sync Update” Window Real Functionality2014: The sync window showed the total number of changes and the number of those that had been successfully downloaded from or posted to the account. What Time Does Super Bowl 2014 Start? Look Up!2014: Google showed the start time at the top of its results. Who’s Tops? Bud Light Is Unseated As Number One Super Bowl Advertiser On Google And Bing2014: Volkswagen garnered the top spot with the most ad impressions on Google. Search In Pics: The Simpsons With Google Glass, Oscar Mayer Car At Google & Google Military Truck2014: The latest images culled from the web, showing what people eat at the search engine companies, how they play, who they meet, where they speak, what toys they have, and more. Adwords For Video Gets Reporting Enhancements2013: Google added three new measurement features to the AdWords for video reporting interface (Reach & Frequency, Column Sets Tailored to Marketing Goals, Geographic Visualization). Jackie Robinson Google Baseball Player Logo2013: The Doodle honored Robinson for his 94th birthday. Google & Bing: We’re Not Involved In “Local Paid Inclusion”2012: A program that guaranteed top listings for local searches on Google, Yahoo and Bing? An “officially approved” one in “cooperation” with those search engines? Not true, said Google and Bing. Report: Search Ad Spend To Rise 27% In 20122012: Search ad spend was expected to grow 27% from 2011 to 2012, up from $15.36 billion to $19.51 billion. And by 2016, it was expected to reach almost $30 billion annually. Matt Cutts Convinces Some South Korean Govt. Websites To Stop Blocking Googlebot2012: Cutts managed to singlehandedly convince some government reps to let Googlebot crawl and index their websites. DOJ Exploring “Search Fairness” With Google As Rivals Protest Potential ITA Licensing Deal2011: FairSearch.org opposed any such potential licensing deal. Review Sites’ Rancor Rises With Prominence of Google Place Pages2011: Google’s relationship with review sites like TripAdvisor and Yelp was as complicated as ever. Google’s Android Now “The World’s Leading Smartphone Platform”: Report2011: More Android handsets were shipped in Q4 2010 than other platforms. Blekko Launches Mobile Apps For iPhone, Android2011: Slashtags and the personalization that Blekko offered were even better suited to the mobile search use case in some respects. Topsy Social Analytics: Twitter Analytics For The Masses (& Free, Too)2011: You could analyze domains, Twitter usernames, or keywords — and they can be compared over four timeframes: one day, a week, two weeks or a month. Google Executive Believed Missing After Egypt Protests2011: Wael Ghonim went missing not long after tweeting about being “very worried” and “ready to die.” Apple CEO: Google Wants To “Kill The iPhone”2010: “We did not enter the search business,” Jobs said. “They entered the phone business. Make no mistake they want to kill the iPhone. We won’t let them.” Google Gets Fearful, Flags Entire Internet As Malware Briefly2009: Due to a human error, Google told users “This site may harm your computer” for every website listed in search results. Google Revenues Up 51 Percent, Social Networking Monetization “Disappointing”2008: Google’s Q4, 2007 revenues were $4.83 billion, compared with $3.21 billion the year before. Google’s Marissa Mayer On Social Search / Search 4.02008: How the search engine was considering using social data to improve its search results. Report: Click Fraud Up 15% In 20072008: The overall industry average click fraud rate rose to 16.6% for Q4 2007. That was up from 14.2% for the same quarter in 2006, and 16.2% in Q3 2007. New “Show Search Options” Broadens Google Maps2008: A pull-down menu allowed users to narrow or expand results for the same query and more easily discover non-traditional content in Google Maps. Google’s Founders & CEO Promised To Work Together Until 20242008: Spoiler alert: Schmidt left Google’s parent company Alphabet for good in February 2020. Google Reports Revenues Up 19 Percent From Previous Quarter2007: Google reported revenues of $3.21 billion for Q4 2006, representing a 67% increase over Q4 2005 revenues of $1.92 billion Google Pushes Back On Click Fraud Estimates, Says Don’t Forget The Back Button2007: Google’s Shuman Ghosemajumdersome said third-party auditing firms don’t appear to be Google, Microsoft, & Yahoo Ask For Help With International Censorship2007: The search engines had to make “moral judgments” about international authorities’ requests for information when they do not have to do the same for US requests. Yahoo To Build New Keyword Research Tool & Wordtracker Launches Free Tool2007: YSM’s public keyword research tool was sporadically offline, but Yahoo had plans to offer a new public keyword research tool. Gmail Locks Out User For Using Greasemonkey & Reports Of Gmail Contacts Disappearing2007: The account was disabled for 24 hours due to “unusual usage.” Yahoo To Build “Brand Universe” To Connect Entertainment Brands2007: Brand Universe would create about 100 websites built around entertainment brands and pull together content from various Yahoo properties. Google Can’t Use “Gmail” Name In Europe2007: Due to a trademark of the term. Boorah Restaurant Reviews: Zagat On Steroids2007: Boorah collected reviews from existing local search and content sites, summarized and enhanced the data and built additional features on top. Q&A With Stephen Baker, CEO Of Reed Business Search2007: What was new with Zibb, a B2B search engines, and the opportunities he saw going forward in B2B search. January 2007: Search Engine Land’s Most Popular StoriesFrom Search Marketing Expo (SMX)Past contributions from Search Engine Land’s Subject Matter Experts (SMEs)These columns are a snapshot in time and have not been updated since publishing, unless noted. Opinions expressed in these articles are those of the author and not necessarily Search Engine Land.
< January 30 | Search Marketing History | February 1 > The post This day in search marketing history: January 31 appeared first on Search Engine Land. via Search Engine Land https://ift.tt/j1tD5ku Google has released three new updates for the GA4 dashboard, allowing advertisers to find information about current properties or accounts. Dig deeper. The following updates were posted by Google on their Analytics Help documentation. Find data stream detailsThe following search terms allow you to open the details for a web or app data stream in the property you are using:
Find the current property and account settingsThe following search terms allow you to open the settings for the property you are using:
The following search terms allow you to open the settings for the account you are using:
Go to other Google Analytics 4 propertiesThe following search terms allow you to navigate to a different Google Analytics 4 property from the one you are using. Analytics shows you up to 7 properties that match the search query.
Why we care. The additional information will help advertisers analyze streams, accounts, and properties in their GA4 accounts. The post New updates for the GA4 search bar appeared first on Search Engine Land. via Search Engine Land https://ift.tt/ZvsPK2y “Fragments” of Yandex’s codebase leaked online last week. Much like Google, Yandex is a platform with many aspects such as email, maps, a taxi service, etc. The code leak featured chunks of all of it. According to the documentation therein, Yandex’s codebase was folded into one large repository called Arcadia in 2013. The leaked codebase is a subset of all projects in Arcadia and we find several components in it related to the search engine in the “Kernel,” “Library,” “Robot,” “Search,” and “ExtSearch” archives. The move is wholly unprecedented. Not since the AOL search query data of 2006 has something so material related to a web search engine entered the public domain. Although we are missing the data and many files that are referenced, this is the first instance of a tangible look at how a modern search engine works at the code level. Personally, I can’t get over how fantastic the timing is to be able to actually see the code as I finish my book “The Science of SEO” where I’m talking about Information Retrieval, how modern search engines actually work, and how to build a simple one yourself. In any event, I’ve been parsing through the code since last Thursday and any engineer will tell you that is not enough time to understand how everything works. So, I suspect there will be several more posts as I keep tinkering. Before we jump in, I want to give a shout-out to Ben Wills at Ontolo for sharing the code with me, pointing me in the initial direction of where the good stuff is, and going back and forth with me as we deciphered things. Feel free to grab the spreadsheet with all the data we’ve compiled about the ranking factors here. Also, shout out to Ryan Jones for digging in and sharing some key findings with me over IM. OK, let’s get busy! It’s not Google’s code, so why do we care?Some believe that reviewing this codebase is a distraction and that there is nothing that will impact how they make business decisions. I find that curious considering these are people from the same SEO community that used the CTR model from the 2006 AOL data as the industry standard for modeling across any search engine for many years to follow. That said, Yandex is not Google. Yet the two are state-of-the-art web search engines that have continued to stay at the cutting edge of technology. 
Software engineers from both companies go to the same conferences (SIGIR, ECIR, etc) and share findings and innovations in Information Retrieval, Natural Language Processing/Understanding, and Machine Learning. Yandex also has a presence in Palo Alto and Google previously had a presence in Moscow. A quick LinkedIn search uncovers a few hundred engineers that have worked at both companies, although we don’t know how many of them have actually worked on Search at both companies. In a more direct overlap, Yandex also makes usage of Google’s open source technologies that have been critical to innovations in Search like TensorFlow, BERT, MapReduce, and, to a much lesser extent, Protocol Buffers. So, while Yandex is certainly not Google, it’s also not some random research project that we’re talking about here. There is a lot we can learn about how a modern search engine is built from reviewing this codebase. At the very least, we can disabuse ourselves of some obsolete notions that still permeate SEO tools like text-to-code ratios and W3C compliance or the general belief that Google’s 200 signals are simply 200 individual on and off-page features rather than classes of composite factors that potentially use thousands of individual measures. Some context on Yandex’s architectureWithout context or the ability to successfully compile, run, and step through it, source code is very difficult to make sense of. Typically, new engineers get documentation, walk-throughs, and engage in pair programming to get onboarded to an existing codebase. And, there is some limited onboarding documentation related to setting up the build process in the docs archive. However, Yandex’s code also references internal wikis throughout, but those have not leaked and the commenting in the code is also quite sparse. Luckily, Yandex does give some insights into its architecture in its public documentation. There are also a couple of patents they’ve published in the US that help shed a bit of light. Namely:
As I’ve been researching Google for my book, I’ve developed a much deeper understanding of the structure of its ranking systems through various whitepapers, patents, and talks from engineers couched against my SEO experience. I’ve also spent a lot of time sharpening my grasp of general Information Retrieval best practices for web search engines. It comes as no surprise that there are indeed some best practices and similarities at play with Yandex. 
Yandex’s documentation discusses a dual-distributed crawler system. One for real-time crawling called the “Orange Crawler” and another for general crawling. Historically, Google is said to have had an index stratified into three buckets, one for housing real-time crawl, one for regularly crawled and one for rarely crawled. This approach is considered a best practice in IR. Yandex and Google differ in this respect, but the general idea of segmented crawling driven by an understanding of update frequency holds. One thing worth calling out is that Yandex has no separate rendering system for JavaScript. They say this in their documentation and, although they have Webdriver-based system for visual regression testing called Gemini, they limit themselves to text-based crawl. 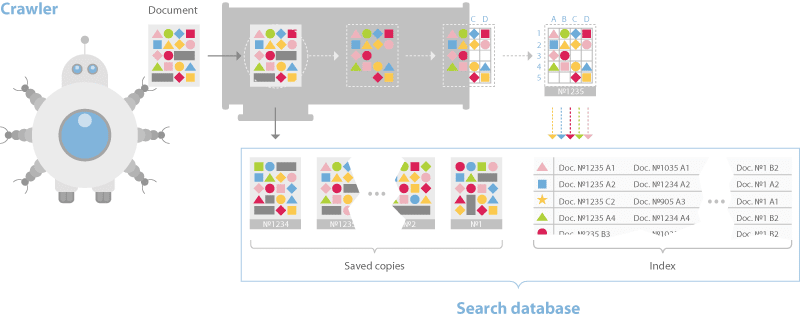
The documentation also discusses a sharded database structure that breaks pages down into an inverted index and a document server. Just like most other web search engines the indexing process builds a dictionary, caches pages, and then places data into the inverted index such that bigrams and trigams and their placement in the document is represented. This differs from Google in that they moved to phrase-based indexing, meaning n-grams that can be much longer than trigrams a long time ago. However, the Yandex system uses BERT in its pipeline as well, so at some point documents and queries are converted to embeddings and nearest neighbor search techniques are employed for ranking. 
The ranking process is where things begin to get more interesting. Yandex has a layer called Metasearch where cached popular search results are served after they process the query. If the results are not found there, then the search query is sent to a series of thousands of different machines in the Basic Search layer simultaneously. Each builds a posting list of relevant documents then returns it to MatrixNet, Yandex’s neural network application for re-ranking, to build the SERP. Based on videos wherein Google engineers have talked about Search’s infrastructure, that ranking process is quite similar to Google Search. They talk about Google’s tech being in shared environments where various applications are on every machine and jobs are distributed across those machines based on the availability of computing power. One of the use cases is exactly this, the distribution of queries to an assortment of machines to process the relevant index shards quickly. Computing the posting lists is the first place that we need to consider the ranking factors. There are 17,854 ranking factors in the codebaseOn the Friday following the leak, the inimitable Martin MacDonald eagerly shared a file from the codebase called web_factors_info/factors_gen.in. The file comes from the “Kernel” archive in the codebase leak and features 1,922 ranking factors. Naturally, the SEO community has run with that number and that file to eagerly spread news of the insights therein. Many folks have translated the descriptions and built tools or Google Sheets and ChatGPT to make sense of the data. All of which are great examples of the power of the community. However, the 1,922 represents just one of many sets of ranking factors in the codebase. 
A deeper dive into the codebase reveals that there are numerous ranking factor files for different subsets of Yandex’s query processing and ranking systems. Combing through those, we find that there are actually 17,854 ranking factors in total. Included in those ranking factors are a variety of metrics related to:
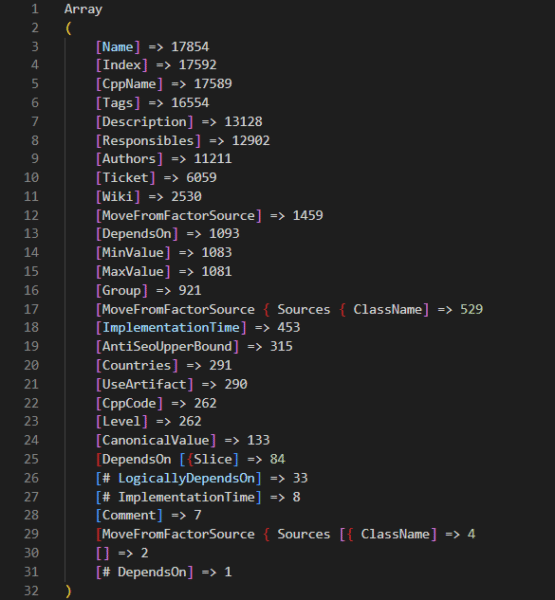
There is also a series of Jupyter notebooks that have an additional 2,000 factors outside of those in the core code. Presumably, these Jupyter notebooks represent tests where engineers are considering additional factors to add to the codebase. Again, you can review all of these features with metadata that we collected from across the codebase at this link. 
Yandex’s documentation further clarifies that they have three classes of ranking factors: Static, Dynamic, and those related specifically to the user’s search and how it was performed. In their own words: 
In the codebase these are indicated in the rank factors files with the tags TG_STATIC and TG_DYNAMIC. The search related factors have multiple tags such as TG_QUERY_ONLY, TG_QUERY, TG_USER_SEARCH, and TG_USER_SEARCH_ONLY. While we have uncovered a potential 18k ranking factors to choose from, the documentation related to MatrixNet indicates that scoring is built from tens of thousands of factors and customized based on the search query. 
This indicates that the ranking environment is highly dynamic, similar to that of Google environment. According to Google’s “Framework for evaluating scoring functions” patent, they have long had something similar where multiple functions are run and the best set of results are returned. Finally, considering that the documentation references tens of thousands of ranking factors, we should also keep in mind that there are many other files referenced in the code that are missing from the archive. So, there is likely more going on that we are unable to see. This is further illustrated by reviewing the images in the onboarding documentation which shows other directories that are not present in the archive. 
For instance, I suspect there is more related to the DSSM in the /semantic-search/ directory. The initial weighting of ranking factorsI first operated under the assumption that the codebase didn’t have any weights for the ranking factors. Then I was shocked to see that the nav_linear.h file in the /search/relevance/ directory features the initial coefficients (or weights) associated with ranking factors on full display. This section of the code highlights 257 of the 17,000+ ranking factors we’ve identified. (Hat tip to Ryan Jones for pulling these and lining them up with the ranking factor descriptions.) For clarity, when you think of a search engine algorithm, you’re probably thinking of a long and complex mathematical equation by which every page is scored based on a series of factors. While that is an oversimplification, the following screenshot is an excerpt of such an equation. The coefficients represent how important each factor is and the resulting computed score is what would be used to score selecter pages for relevance. 
These values being hard-coded suggests that this is certainly not the only place that ranking happens. Instead, this function is most likely where the initial relevance scoring is done to generate a series of posting lists for each shard being considered for ranking. In the first patent listed above, they talk about this as a concept of query-independent relevance (QIR) which then limits documents prior to reviewing them for query-specific relevance (QSR). The resulting posting lists are then handed off to MatrixNet with query features to compare against. So while we don’t know the specifics of the downstream operations (yet), these weights are still valuable to understand because they tell you the requirements for a page to be eligible for the consideration set. However, that brings up the next question: what do we know about MatrixNet? There is neural ranking code in the Kernel archive and there are numerous references to MatrixNet and “mxnet” as well as many references to Deep Structured Semantic Models (DSSM) throughout the codebase. The description of one of the FI_MATRIXNET ranking factor indicates that MatrixNet is applied to all factors. Factor { Index: 160 CppName: “FI_MATRIXNET” Name: “MatrixNet” Tags: [TG_DOC, TG_DYNAMIC, TG_TRANS, TG_NOT_01, TG_REARR_USE, TG_L3_MODEL_VALUE, TG_FRESHNESS_FROZEN_POOL] Description: “MatrixNet is applied to all factors – the formula” } There’s also a bunch of binary files that may be the pre-trained models themselves, but it’s going to take me more time to unravel those aspects of the code. What is immediately clear is that there are multiple levels to ranking (L1, L2, L3) and there is an assortment of ranking models that can be selected at each level. 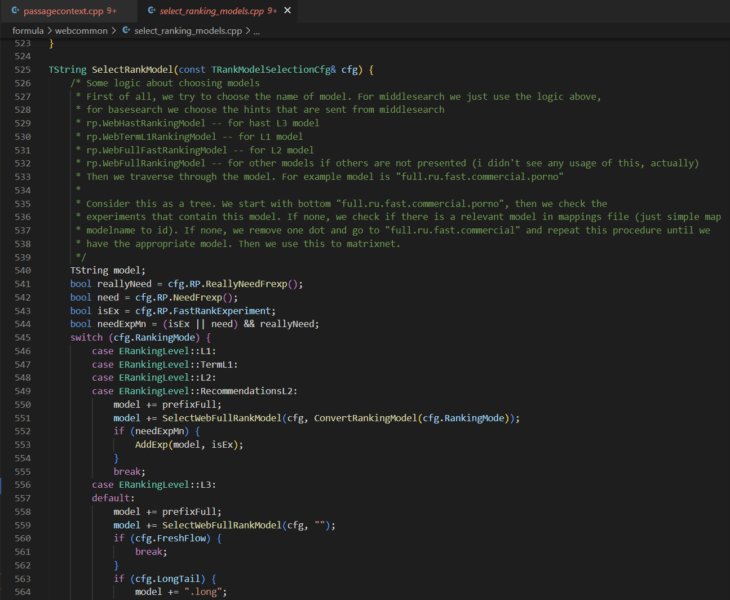
The selecting_rankings_model.cpp file suggests that different ranking models may be considered at each layer throughout the process. This is basically how neural networks work. Each level is an aspect that completes operations and their combined computations yield the re-ranked list of documents that ultimately appears as a SERP. I’ll follow up with a deep dive on MatrixNet when I have more time. For those that need a sneak peek, check out the Search result ranker patent. For now, let’s take a look at some interesting ranking factors. Top 5 negatively weighted initial ranking factorsThe following is a list of the highest negatively weighted initial ranking factors with their weights and a brief explanation based on their descriptions translated from Russian.
In summary, these factors indicate that, for the best score, you should:
Everything else in this list is beyond your control. Top 5 positively weighted initial ranking factorsTo follow up, here’s a list of the highest weighted positive ranking factors.
In other words:
There are plenty of unexpected initial ranking factorsWhat’s more interesting in the initial weighted ranking factors are the unexpected ones. The following is a list of seventeen factors that stood out.
The primary takeaway from reviewing these odd rankings factors and the array of those available across the Yandex codebase is that there are many things that could be a ranking factor. I suspect that Google’s reported “200 signals” are actually 200 classes of signal where each signal is a composite built of many other components. In much the same way that Google Analytics has dimensions with many metrics associated, Google Search likely has classes of ranking signals composed of many features. Yandex scrapes Google, Bing, YouTube and TikTokThe codebase also reveals that Yandex has many parsers for other websites and their respective services. To Westerners, the most notable of those are the ones I’ve listed in the heading above. Additionally, Yandex has parsers for a variety of services that I was unfamiliar with as well as those for its own services. 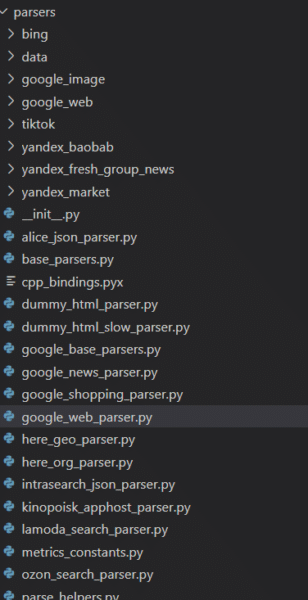
What is immediately evident, is that the parsers are feature complete. Every meaningful component of the Google SERP is extracted. In fact, anyone that might be considering scraping any of these services might do well to review this code. 
There is other code that indicates Yandex is using some Google data as part of the DSSM calculations, but the 83 Google named ranking factors themselves make it clear that Yandex has leaned on the Google’s results pretty heavily. 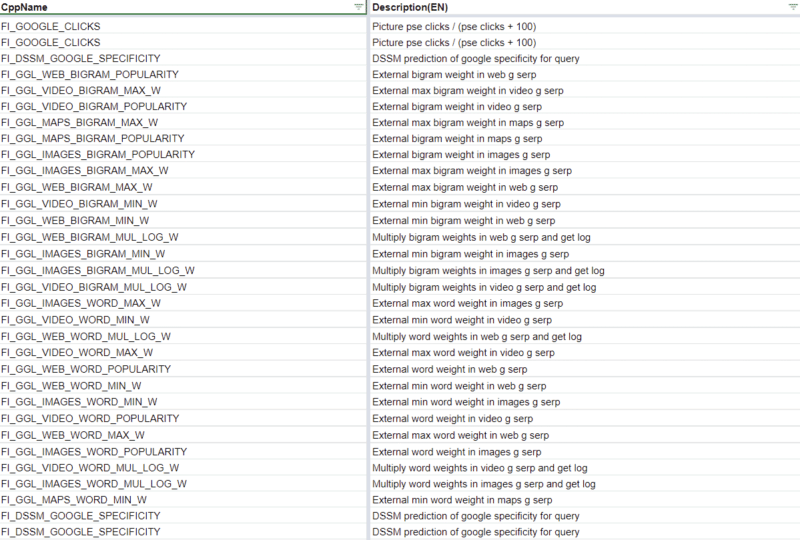
Obviously, Google would never pull the Bing move of copying another search engine’s results nor be reliant on one for core ranking calculations. Yandex has anti-SEO upper bounds for some ranking factors315 ranking factors have thresholds at which any computed value beyond that indicates to the system that that feature of the page is over-optimized. 39 of these ranking factors are part of the initially weighted factors that may keep a page from being included in the initial postings list. You can find these in the spreadsheet I’ve linked to above by filtering for the Rank Coefficient and the Anti-SEO column. 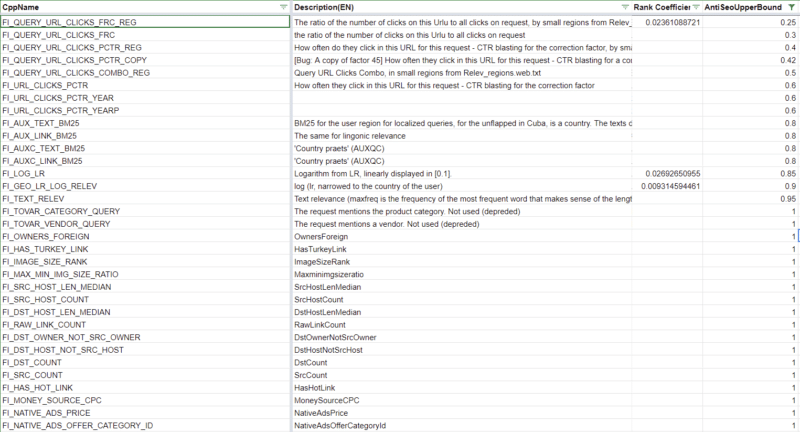
It’s not far-fetched conceptually to expect that all modern search engines set thresholds on certain factors that SEOs have historically abused such as anchor text, CTR, or keyword stuffing. For instance, Bing was said to leverage the abusive usage of the meta keywords as a negative factor. Yandex boosts “Vital Hosts”Yandex has a series of boosting mechanisms throughout its codebase. These are artificial improvements to certain documents to ensure they score higher when being considered for ranking. Below is a comment from the “boosting wizard” which suggests that smaller files benefit best from the boosting algorithm. 
There are several types of boosts; I’ve seen one boost related to links and I’ve also seen a series of “HandJobBoosts” which I can only assume is a weird translation of “manual” changes. 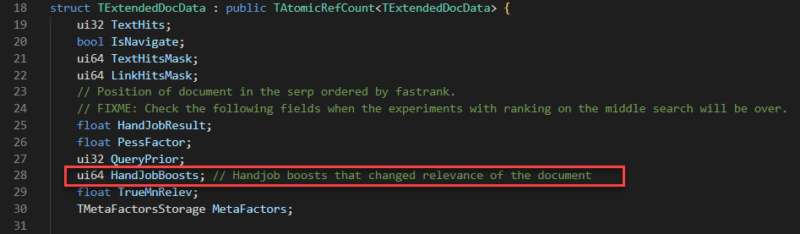
One of these boosts I found particularly interesting is related to “Vital Hosts.” Where a vital host can be any site specified. Specifically mentioned in the variables is NEWS_AGENCY_RATING which leads me to believe that Yandex gives a boost that biases its results to certain news organizations. 
Without getting into geopolitics, this is very different from Google in that they have been adamant about not introducing biases like this into their ranking systems. The structure of the document serverThe codebase reveals how documents are stored in Yandex’s document server. This is helpful in understanding that a search engine does not simply make a copy of the page and save it to its cache, it’s capturing various features as metadata to then use in the downstream rankings process. The screenshot below highlights a subset of those features that are particularly interesting. Other files with SQL queries suggest that the document server has closer to 200 columns including the DOM tree, sentence lengths, fetch time, a series of dates, and antispam score, redirect chain, and whether or not the document is translated. The most complete list I’ve come across is in /robot/rthub/yql/protos/web_page_item.proto. 
What’s most interesting in the subset here is the number of simhashes that are employed. Simhashes are numeric representations of content and search engines use them for lightning fast comparison for the determination of duplicate content. There are various instances in the robot archive that indicate duplicate content is explicitly demoted. 
Also, as part of the indexing process, the codebase features TF-IDF, BM25, and BERT in its text processing pipeline. It’s not clear why all of these mechanisms exist in the code because there is some redundancy in using them all. Link factors and prioritizationHow Yandex handles link factors is particularly interesting because they previously disabled their impact altogether. The codebase also reveals a lot of information about link factors and how links are prioritized. Yandex’s link spam calculator has 89 factors that it looks at. Anything marked as SF_RESERVED is deprecated. Where provided, you can find the descriptions of these factors in the Google Sheet linked above. 

Notably, Yandex has a host rank and some scores that appear to live on long term after a site or page develops a reputation for spam. Another thing Yandex does is review copy across a domain and determine if there is duplicate content with those links. This can be sitewide link placements, links on duplicate pages, or simply links with the same anchor text coming from the same site. 
This illustrates how trivial it is to discount multiple links from the same source and clarifies how important it is to target more unique links from more diverse sources. What can we apply from Yandex to what we know about Google?Naturally, this is still the question on everyone’s mind. While there are certainly many analogs between Yandex and Google, truthfully, only a Google Software Engineer working on Search could definitively answer that question. Yet, that is the wrong question. Really, this code should help us expand our thinking about modern search. Much of the collective understanding of search is built from what the SEO community learned in the early 2000s through testing and from the mouths of search engineers when search was far less opaque. That unfortunately has not kept up with the rapid pace of innovation. Insights from the many features and factors of the Yandex leak should yield more hypotheses of things to test and consider for ranking in Google. They should also introduce more things that can be parsed and measured by SEO crawling, link analysis, and ranking tools. For instance, a measure of the cosine similarity between queries and documents using BERT embeddings could be valuable to understand versus competitor pages since it’s something that modern search engines are themselves doing. Much in the way the AOL Search logs moved us from guessing the distribution of clicks on SERP, the Yandex codebase moves us away from the abstract to the concrete and our “it depends” statements can be better qualified. To that end, this codebase is a gift that will keep on giving. It’s only been a weekend and we’ve already gleaned some very compelling insights from this code. I anticipate some ambitious SEO engineers with far more time on their hands will keep digging and maybe even fill in enough of what’s missing to compile this thing and get it working. I also believe engineers at the different search engines are also going through and parsing out innovations that they can learn from and add to their systems. Simultaneously, Google lawyers are probably drafting aggressive cease and desist letters related to all the scraping. I’m eager to see the evolution of our space that’s driven by the curious people who will maximize this opportunity. But, hey, if getting insights from actual code is not valuable to you, you’re welcome to go back to doing something more important like arguing about subdomains versus subdirectories. The post Yandex scrapes Google and other SEO learnings from the source code leak appeared first on Search Engine Land. via Search Engine Land https://ift.tt/f3Lpkvz |
Archives
April 2024
Categories
|
